As big data becomes more and more popular, the word big data is getting more and more popular, and the field of big data applications is becoming more and more extensive. So what are the big data analysis tools?
Big data is a broad term that refers to data sets that are so large and complex that they require specially designed hardware and software tools to process. This data set is usually the size of trillion or EB. These data sets are collected from a variety of sources: sensors, climate information, public information, such as magazines, newspapers, articles. Other examples of big data generation include purchase transaction records, web logs, medical records, event monitoring, video and image archives, and large e-commerce. Big data analytics is the process of finding patterns, correlations, and other useful information in the process of researching large amounts of data to help companies better adapt to change and make more informed decisions.
First, HadoopHadoop is a software framework that enables distributed processing of large amounts of data. But Hadoop is handled in a reliable, efficient, and scalable way. Hadoop is reliable because it assumes that the computational elements and storage will fail, so it maintains multiple copies of the working data, ensuring that the processing can be redistributed for failed nodes. Hadoop is efficient because it works in parallel and speeds up processing through parallel processing. Hadoop is also scalable and can handle petabytes of data. In addition, Hadoop relies on a community server, so its cost is low and anyone can use it.

Hadoop is a distributed computing platform that allows users to easily architect and use. Users can easily develop and run applications that process massive amounts of data on Hadoop. It has the following main advantages:
1. High reliability. Hadoop's ability to store and process data in bits is worthy of trust.
2. High scalability. Hadoop distributes data and performs computational tasks among the clusters of available computers. These clusters can be easily scaled to thousands of nodes.
3. High efficiency. Hadoop is able to dynamically move data between nodes and ensure the dynamic balance of each node, so processing is very fast.
4. High tolerance. Hadoop automatically saves multiple copies of your data and automatically redistributes failed tasks.
Hadoop comes with a framework written in the Java language, so it is ideal for running on a Linux production platform.
Applications on Hadoop can also be written in other languages, such as C++.
Second, HPCCAbbreviation for HPCC, High Performance CompuTIng and CommunicaTIons.
In 1993, the US Federal Coordinating Council for Science, Engineering, and Technology submitted a report to the Congress on “Major Challenge Project: High Performance Computing and Communications,†a report known as the HPCC Program, the US President’s Science Strategy Program. The aim is to solve a number of important scientific and technological challenges by strengthening research and development. The HPCC is a US implementation of the information superhighway. The implementation of the plan will cost tens of billions of dollars. Its main objectives are to develop scalable computing systems and related software to support terabit network transmission performance. Megabit network technology, expanding research and educational institutions and network connectivity.
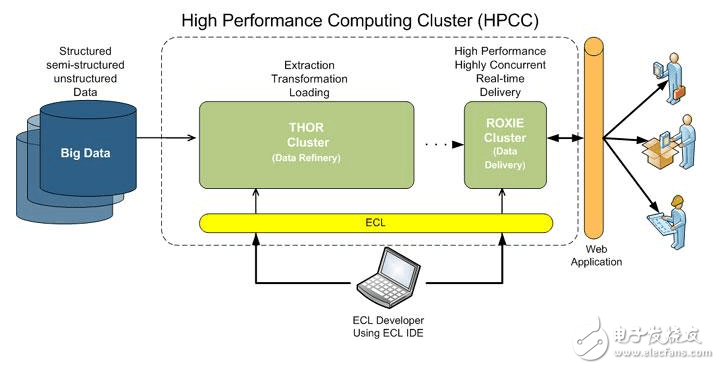
The project consists of five main components:
1. High-performance computer system (HPCS), including research on future generations of computer systems, system design tools, advanced typical systems, and evaluation of legacy systems;
2. Advanced Software Technology and Algorithm (ASTA), software support, new algorithm design, software branch and tools, computational computing and high performance computing research center with huge challenges;
3. National Research and Education Grid (NREN), with research and development of medium-station and 1 billion-bit transmission;
4. Basic Research and Human Resources (BRHR), with basic research, training, education, and course materials, designed to reward investigators-starting, long-term surveys to increase the flow of innovation in scalable high-performance computing. Increase the pooling of skilled and trained personnel by improving education and high-performance computing training and communication, and provide the necessary infrastructure to support these surveys and research activities;
5. Information Infrastructure Technology and Applications (IITA) aims to ensure the United States' leading position in advanced information technology development.
Third, StormStorm is free open source software, a distributed, fault-tolerant real-time computing system. Storm can handle huge data streams with great reliability for processing bulk data from Hadoop. Storm is very simple, supports many kinds of programming languages, and is very interesting to use. Storm is open sourced by Twitter. Other well-known application companies include Groupon, Taobao, Alipay, Alibaba, Music, Admaster and more.
Storm has many application areas: real-time analytics, online machine learning, non-stop computing, distributed RPC (far-process calling protocol, a request for services from remote computer programs over a network), ETL (abbreviation for ExtracTIon-TransformaTIon-Loading, That is, data extraction, conversion, and loading) and so on. Storm's processing speed is amazing: after testing, each node can process 1 million data tuples per second. Storm is scalable, fault tolerant, and easy to set up and operate.
To help business users find more effective ways to speed up Hadoop data queries, the Apache Software Foundation recently launched an open source project called "Drill." Apache Drill implements Google's Dremel.
According to Tomer Shiran, product manager of Hadoop vendor MapR Technologies, "Drill" has been implemented as an Apache incubator project and will continue to be promoted to global software engineers.
The project will create an open source version of the Google Dremel Hadoop tool (Google uses the tool to speed up the Internet application for Hadoop data analysis tools). And "Drill" will help Hadoop users achieve faster querying of massive data sets.
The "Drill" project is also inspired by Google's Dremel project: it helps Google implement the analysis of massive data sets, including analyzing and crawling Web documents, tracking application data installed on the Android Market, analyzing spam, and analyzing Test results on Google Distributed Build System and more.
By developing the "Drill" Apache open source project, organizations will be able to build Drill's API interfaces and flexible and powerful architecture to help support a wide range of data sources, data formats and query languages.

The portable WiFi mini Home Projector has reduced the size and weight on the basis of the traditional projector, which is convenient to carry out and is no longer limited to one location. The connection is simple, the projector can be started with only a power cord, and the playback resources can be obtained by connecting WiFi and USB
led mini projector,best mini projector,wifi mini home projector,mini projector with wifi,mini projector wifi bluetooth
Shenzhen Happybate Trading Co.,LTD , https://www.happybateprojectors.com