Although the research of fault-tolerant control faces unprecedented challenges, in recent years, relevant research fields, such as robust control theory, fuzzy control, and the deepening and development of neural network control research have also brought good research to fault-tolerant control. Opportunities provide sufficient conditions.
The rapid development of computer control technology, artificial intelligence and other technologies has made the possibility of fault-tolerant control technology applied in practical engineering more and more.
The origin of the concept of fault tolerance
Fault tolerance: It is an allowable error. It means that when one or more critical parts of the equipment fail, it can automatically detect and diagnose, and take corresponding measures to ensure that the equipment maintains its specified functions, or sacrifices performance to ensure that the equipment is acceptable. Continue working within the scope.
Errors are generally divided into two categories: the first category is congenital inherent errors, such as errors caused in the production process of components, and errors in the design process of circuits and programs. This type of error needs to be removed, replaced or corrected and cannot be tolerated. The second type is an acquired fault, which is caused by a defect caused by the equipment running. This type of failure has the distinction of transient, intermittent and permanent.
Fault tolerance technology is an important way to improve system reliability. Commonly used fault tolerance methods are hardware fault tolerance, software fault tolerance, information fault tolerance, and time fault tolerance.
There are generally two ways to improve the reliability of the system: 1. Use careful design and quality control methods to minimize the probability of failure. 2. Exchange reliability at the expense of redundant resources.
The use of the former method to improve the reliability of the system is limited, and further improvement is necessary to adopt fault tolerance technology.
Fault-tolerant control technology developed earlier in foreign countries and was one of the founders of the computer, proposed by the American Hungarian mathematician von Neumann. With the rapid development and widespread application of microcomputers in the 1980s, fault-tolerant technology has also developed rapidly, and fault-tolerant technology has been applied to various environments.
China's fault-tolerant technology is also developing rapidly. Some important workplaces such as aerospace and power plants now use fault-tolerant technology.
1. Definition of intelligent fault tolerance
Intelligent Fault-Tolerance (IFT): Before the failure or impending failure of one or more key components during operation, the artificial intelligence theory and method are used to automatically compensate and suppress the fault by taking effective measures. Elimination, repair, to ensure that the equipment continues to operate safely, efficiently, reliably, or at the expense of performance loss, to ensure that the equipment completes its intended function within the specified time.
Hardware Intelligent Fault Tolerant (HIFT) mainly uses hardware redundancy technology. The basic idea is to equip key components of the device with multiple similar or identical components. Once the device is detected and diagnosed, it can be switched to the backup component immediately to achieve fault tolerance.
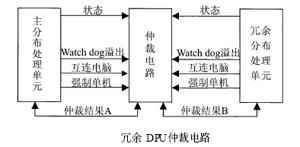
Two redundant structure schematic
2, the classification of hardware intelligent fault tolerance
Hardware intelligent fault tolerance can be divided into: static redundancy, dynamic redundancy and hybrid redundancy.
Static redundancy fault tolerance is through voting and comparison of faults in the shielded system, as shown in the figure
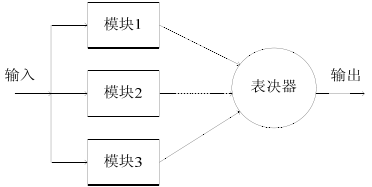
Three-mode redundancy (static redundancy) TMR system structure
The main features of static redundancy fault tolerance are:
(1) Since the fault is shielded, it is not necessary to identify the fault;
(2) Easy to convert with non-redundant systems;
(3) All modules consume energy.
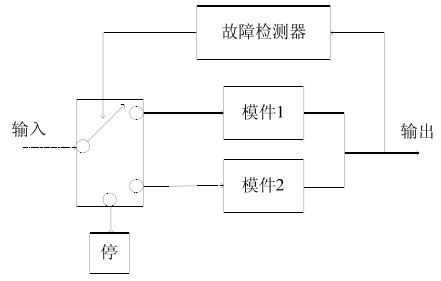
The main way of dynamic redundancy is that multiple modules run in succession to keep the device working properly. When a fault occurs in the working module, a spare module immediately takes over the faulty module and puts it into operation.
The main features of dynamic redundancy fault-tolerant control are:
(1) Only one module consumes energy;
(2) The number of modules can change with the task and will not affect the system work;
(3) Any failure in the conversion device and the detection device will cause the system to fail.
Dynamic redundant fault tolerant control structure
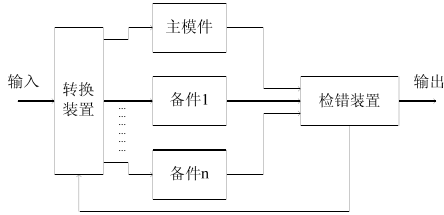
Hybrid redundancy, dynamic redundancy, and static redundancy are usually expressed in terms of H(n, k), as shown in the following figure. In the figure, V is the voter, n is the total number of modules, k is the number of modules that implement static redundancy by voting, and the remaining NK modules are used as backups of the modules in the voting system. When one module in the k modules participating in the voting (usually k>=3) fails, the backup replaces the module to participate in the voting, maintaining the integrity of the static redundancy system. When all backups have been replaced, the system becomes a general voting system.
For example, in a logic system composed of hardware, the voter is implemented by a switch circuit, and the voting in the software needs to be implemented by software assertion SA (Software Assertions). Software assertion is the condition for making a judgment about the correctness of a process or function when the software is running in the host system.
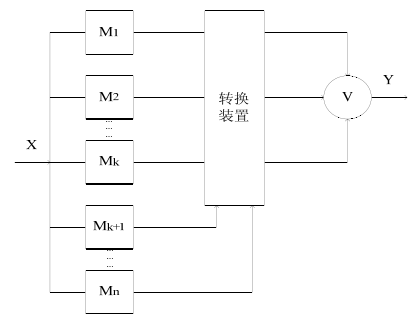
H(n,k) system structure
3. Implementation method of intelligent fault tolerance
The implementation methods of intelligent fault tolerance are divided into: (1) fault signal detection; (2) fault feature identification; (3) fault state prediction; (4) fault repair decision; (5) fault fault tolerance control.
The purpose of fault tolerance is to take appropriate fault-tolerant measures for different fault sources and fault characteristics, and compensate, eliminate or repair the faults to ensure that the equipment continues to operate safely and reliably, or at the expense of performance loss to ensure that the equipment is at Complete its basic functions within the specified time.
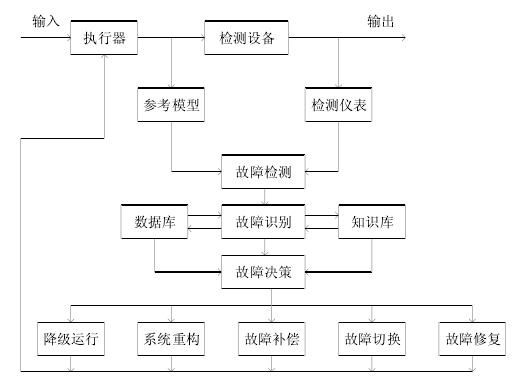
Fault tolerant control process block diagram
Redundancy technology
High reliability is the first requirement of process control systems. In order to achieve high reliability and low failure rate, we usually use redundancy technology in the design and application of control systems. Reasonable redundancy design will greatly improve the reliability of the system, but it also increases the complexity of the system and the difficulty of design. How to control the redundant design of the control system reasonably and effectively is worthy of study.
1, redundant technology concept
Redundancy is the addition of redundant equipment to ensure that the system works more reliably and safely.
Redundant classification methods are diverse. According to the location in the system, redundancy can be divided into component level, component level and system level; according to the degree of redundancy, it can be divided into 1:1 redundancy, 1:2 redundancy. I, 1:n redundancy and so on.
In the current situation of increasing component reliability, compared with other forms of redundancy, 1:1 component-level thermal redundancy is an effective and relatively simple, flexible configuration of redundant technology implementation, such as I/O card redundancy, power redundancy, main controller redundancy, etc.
Therefore, most of the current mainstream process control systems at home and abroad use this approach. Of course, there are also successful examples of component-level or multiple redundancy combinations in some partial designs.
2. Key technologies for controlling system redundancy
Redundancy is an advanced reliability design technique. 1:1 thermal redundancy, also known as dualization, is one of the effective redundancy methods, but it is not a simple parallel operation of two components, but requires hardware, software, communication and other collaborative work to achieve. The two components that are mutually redundant form an organic whole, which usually includes the following technical points:
1) Information synchronization technology
It is the premise of the Bumpless switching technology between the working and standby components. Only the high-speed and effective information synchronization according to the real-time requirements of the control ensures that the working and standby components work in unison, and the redundant components can be realized. No disturbance switching.
In the hot standby mode, one of the blocks is in working state (work card), which realizes the functions of data acquisition, calculation, control output, network communication, etc.; while the other block is in standby state (standby card), which tracks the working card in real time. Internal control state (ie state synchronization). The positive/negative logic between the working/standby cards is mutually exclusive, that is, one is the working card and the other must be the standby card; and there are redundant control circuits (also called working/standby control circuits) and information between them. The communication circuit coordinates the operation of the two cards at the same time and in an orderly manner to ensure the identity of the external input and output characteristics, that is, for the user to use, it can be considered that there is only one component. Generally, in the design, the working state and the spare parts are synchronized by the high-speed redundant communication channel (serial or parallel) to realize the mutual check of the running state and the control state (such as configuration information, output valve position, control parameters, etc.).
2) Fault detection technology
In order to ensure that the system puts the redundant part into operation in the event of a fault, it must have a highly accurate online fault detection technology to realize fault discovery, fault location, fault isolation and fault alarm. Fault detection includes power supplies, microprocessors, data communication links, data buses, and I/O status. The fault diagnosis includes fault self-diagnosis and fault mutual inspection (work and mutual check between spare cards)
3) Fault arbitration technology and switching technology
After accurately and timely detecting the fault, it is also necessary to determine the fault location in time, analyze the severity of the fault, rely on the redundant control circuit mentioned above, analyze, compare and arbitrate the working and standby fault states to determine whether work is needed. / State switch between standbys. Switching control to redundant spare parts must also ensure fast, safe, and undisturbed. When a component in working condition fails (power outage, reset, software failure, hardware failure, etc.) or the failure of the working component is more serious than the spare component, the spare component must quickly and uninterruptedly take over all control tasks of the working component, to the site. Control does not have any effect. At the same time, the switching time should be in the order of milliseconds or even microseconds, so that the external control object is out of control or the detection information is invalid due to the failure of the component. In addition, it is necessary to send an alarm through network communication or local LED display as soon as possible to inform the user of the faulty parts and fault conditions for timely maintenance.
4) Hot plug technology
In order to ensure high reliability of the fault-tolerant system, the MTBR of the average repair time of the system must be minimized. To do this, efforts should be made to improve unit independence, repairability, and fault maintainability. Online maintenance and replacement of faulty components is also an important part of the redundancy technology. It is the key to realizing the rapid repair technology of faulty components of the control system. The hot-swap function of the components can be added or replaced without interrupting the normal control functions of the system, allowing the system to operate smoothly.
5) Fault isolation technology
In the case of redundant design, it is necessary to consider that the probability of failure between work and spare parts should be as small as possible (0.01%), and the fault is considered to be isolated. This ensures that when a component in standby state fails, it will not affect the normal operation of redundant working components or other related components, and ensure the effectiveness of redundancy.
With the rapid development of industrial automation, the industrial sector has placed increasing demands on the reliability of production equipment and control systems. Redundancy technology increases the reliability of the control system and meets the application needs of special industrial sectors.
The terminal is used to facilitate the connection of wires. It is actually a piece of metal enclosed in insulating plastic. There are holes at both ends to insert wires. There are screws for fastening or loosening, such as two wires, sometimes Need to connect, sometimes need to be disconnected, then you can use the terminal to connect them, and can be disconnected at any time, without having to solder or twist them together, very convenient and fast.
Power Terminal Block,High Power Terminal Connector Block,Power Terminal Block Connector,Ac Power Terminal Block
Sichuan Xinlian electronic science and technology Company , https://www.sztmlchs.com