Principles of audio encoding and decoding
Each CD disc can reproduce a two-channel stereo signal for up to 74 minutes. The VCD video disc player must simultaneously reproduce sound and images. The image signal data needs to be compressed, and the sound signal data should also be compressed. Otherwise, the sound signal is difficult to store in the VCD disc.
1. Sound compression coding principle The structure of the sound signal is simpler than the image signal. The audio signal compression method is similar to the image signal compression technology, and redundant information should also be removed from the audio signal. The hearing sensitivity of the human ear to the audio signal has its regularity, and it has special sensitivity characteristics for the sounds of different frequency bands or different sound pressure levels. In the process of compressing sound data, the auditory psychological characteristics such as hearing threshold and masking effect are mainly used.
1. Threshold and masking effect
(1) Threshold characteristics The human ear has different hearing sensitivities to sounds of different frequencies. It has low hearing sensitivities to low frequency bands (such as below 100 Hz) and ultra-high frequency bands (such as above 16KHZ). At this time, the hearing sensitivity is significantly improved. Generally, this phenomenon is called the threshold characteristic of the human ear. If such a hearing characteristic is represented by a curve, it is called a threshold characteristic curve of the human ear, and the threshold characteristic curve reflects the numerical limit of the characteristic. Discarding the sound below the curve limit has no effect on the actual listening effect of the human ear. These sounds are redundant information.
In the sound compression coding process, the sound signal of the audible frequency band above the threshold curve should be retained. It is the main component of the audible frequency band, and those signals with inaudible frequency bands are not easy to be detected. Strong signals should be retained, and weak signals should be ignored. With such processed sound, the human ear hardly perceives its distortion. In the actual sound compression coding process, the sound data in different frequency bands should also be quantized. The insensitive frequency bands of the human ear can be quantized with a coarser quantization step, and some secondary information can be discarded; while the sensitive frequency bands of the human ear can be quantized with a smaller quantization step, which uses more code bits to transmit.
(2) Masking effect Masking effect is another important physiological characteristic of human ear. If there are two kinds of sound signals in a narrow frequency band, when one intensity is greater than the other, the hearing threshold of the human ear will increase, and the human ear can hear the sound signal at a large volume, and the sound at a low frequency near it The signal is not audible, it seems that the low volume signal is masked by the high volume signal. The phenomenon of not hearing this sound due to the presence of other sound signals is called the masking effect.
According to the masking characteristics of the human ear, the low-volume signal near the high volume can be discarded without affecting the actual listening effect. Even if these low-volume signals are retained, the human ear cannot hear their existence. It belongs to redundant information in the sound signal. By discarding these signals, the total amount of sound data can be further compressed.
After careful observation, the masking effect is divided into two categories, one is the simultaneous masking effect, and the other is the short-term masking effect. Among them, the simultaneous masking effect means that there is a weak signal and a strong signal at the same time, the frequency of the two is close, the strong signal will increase the hearing threshold of the weak signal, and when the hearing threshold of the weak signal is raised to a certain level, the human ear will not hear. To weak signals. For example, two sounds of A and B appear at the same time. If the hearing threshold of A sound is 50dB, the presence of another B sound at a different frequency will raise the threshold of A sound to 64-68dB. For example, if it is 68dB, then the value (68 ~ 50) dB = 18dB, this value is called the masking amount. The strong B is claimed as the masking sound, while the weaker A is claimed as the masked sound. The above masking phenomenon shows that if there is only A sound, the sound with a sound pressure level above 50dB can be transmitted, and the sound below 50dB will not be heard; if B sound occurs at the same time, B sound has a simultaneous masking effect, making A sound The sound below the sound pressure level of 68dB is also inaudible, that is, the A sound between 50 and 68dB is also inaudible to the human ear. These sounds do not need to be transmitted, and even if they are transmitted, they can only be transmitted at sound pressure levels above 68dB. sound. In short, in order to increase the threshold of one sound, another sound can be set at the same time, and a part of the sound data can be compressed using this method. In a very quiet environment, the human ear can hear sounds of various frequencies with very low sound pressure levels, but the masking threshold for low-frequency sounds and high-frequency sounds is high, that is, the hearing is not sensitive. The research also found that the stronger the masking sound, the stronger the masking effect; when the frequency difference between the masking sound and the masked sound is smaller, the masking effect is more obvious, and when the two frequencies are equal, the masking effect is the best; the low-frequency sound (set to B ) Can effectively mask high-frequency sounds (set to A), while high-frequency sounds (set to B) can hardly mask low-frequency sounds (set to A). Therefore, when inputting a signal, when adding more noise in the masked frequency band, the human ear will not feel the difference from the original signal. The above-mentioned simultaneous masking effect, also known as the frequency-domain masking effect, mainly reflects the influence on the masking effect in the frequency domain. In sound compression coding, the masking effect of single frequency sound is used more.
If the A sound and the B sound do not appear at the same time, the masking effect can also occur, which is called the short-term masking effect. Short-term masking can be divided into two types, the role can continue for a period of time, namely backward masking and forward masking. Backward masking means that after the masking sound B disappears, its masking effect can continue for a period of time, generally up to 0.5 to 2 seconds. The masking mechanism is caused by the storage effect of the human ear. Forward masking means that the masking sound A appears after a period of time and the masking sound B appears. As long as the sound separation of A and B is not too large (generally within 0.05 to 0.2 seconds), B can also mask A. The masking mechanism is that when the sound A has not yet been accepted by the human ear, the powerful sound B has arrived. In practice, backward masking has higher application value. The short-term masking effect has strong time-domain structure characteristics, so it is also called the time-domain masking effect. In sound compression coding, both the frequency and time domain masking effects of good human ears should be considered.
2. The principle of subband coding
(1) Subband encoding and decoding process The so-called subband encoding technology is a technology that transforms the original signal from the time domain to the frequency domain, and then divides it into several subbands, and digitally encodes them. It uses a band-pass filter (BPF) group to divide the original signal into several (for example, m) sub-bands (referred to as sub-bands).
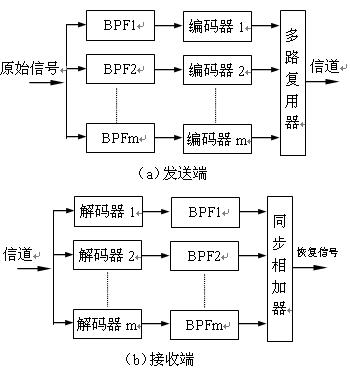
The reverse process at the sending end is realized at the receiving end. Input sub-band coded data stream, send each sub-band signal to the corresponding digital decoding circuit (a total of m) for digital demodulation, pass through various channels of low-pass filters (m channels), and re-demodulate. The frequency domain of the sub-band is restored to the original distributed state of the original signal. Finally, the output signals of each sub-band are sent to a synchronous adder, and the original signal is restored through addition, and the restored signal is very similar to the original signal.
(2) Application of sub-band coding The sub-band coding technology has outstanding advantages. First of all, the amplitude value of each frequency component of the sound spectrum is different. If appropriate proportional coefficients are assigned to different subbands, the number of quantization levels and the corresponding reconstruction errors of each subband can be more reasonably controlled, so that the code rate Accurately match the characteristics of the signal source of each subband. Generally, in the vicinity of the low-frequency pitch, a larger number of bits is used to represent the sampled value, while in the high-frequency band, smaller coded bits can be allocated. Secondly, by reasonably allocating the number of bits in different subbands, the shape of the total reconstruction error spectrum can be controlled, and by combining with the acoustic mental model, the noise spectrum can be formed according to the subjective noise perception characteristics of the human ear. Therefore, the use of the human ear auditory masking effect can save a large number of bits.
When using sub-band coding, the auditory masking effect is used for processing. It deletes some subband signals or greatly reduces the number of bits, which can significantly compress the total amount of data transmitted. For example, subbands without signal frequency components, subbands with signal frequencies masked by noise, and subbands with signal frequency components masked by adjacent strong signals can all be deleted. In addition, the amount of transmission information of the entire system is related to the frequency band range and dynamic range of the signal. The dynamic range is determined by the number of quantization bits. If a reasonable number of bits is introduced into the signal, different subbands can be given as needed Different bit numbers can also compress the amount of information.
2. MPEG-1 audio coding block diagram
1. Basis of MPEG-1 audio coding
The MPEG-1 audio compression coding standard uses psychological algorithms. The perceptual model is used to delete those sound data that are not sensitive to hearing, so that the quality of the reconstructed sound is not significantly reduced. It uses sub-band coding technology to obtain auditory masking thresholds for different sub-bands according to psychoacoustic models; it dynamically quantizes the sampling values ​​of each sub-band. According to the change rule of the low volume signal masking threshold caused by the high volume signal in different frequency bands, different quantization steps are given to different frequency bands in order to retain the main signal, while discarding the components that have little effect on the auditory effect, after data compression , Can obtain a reasonable bit stream, reduce the original sound transmission code rate of about 1.5Mbit / s to 0.3Mbit / s, that is, the compression rate can reach 1/5.
2. Encoding flowchart 2.3.2 is a block diagram of MPEG-1 audio compression encoding based on MUSICAM (Mask Mode Universal Subband Encoding and Multiplexing). The input signal is a sampled binary PCM digital audio signal. The sampling frequency can be 44.1KHz, 48KHz or 32KHz. The code value of the audio digital signal is proportional to the amplitude and frequency of the original sampled signal. 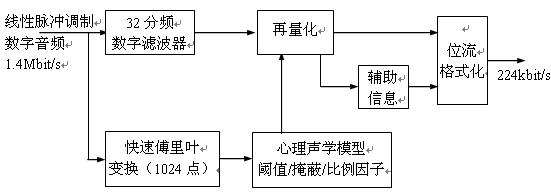
The digital audio signal first enters the digital filter bank, which is divided into 32 sub-bands of equal bandwidth, and 32 sub-band data signals can be output by the digital filter. This processing method is similar to the DCT transformation of the image coded signal, but it is not divided into 64 kinds of cosine frequency information like the image signal. Here it is only divided into 32 subbands, that is, the audio data stream is changed to a combination of 32 frequencies. The resolution of sound is lower than that of images, and this processing method is feasible. Then, the sound data of 32 sub-bands is re-quantized to recompress the amount of data. The quantization step size is different for each sub-band, and the quantization step size is determined according to the hearing threshold and masking effect of the human ear. The compressed data after the quantization process retains the main part of the sound information, and discards the sound information with less influence on the auditory effect.
The input signal into the coding system, the shunt part of the signal is sent to the parallel 1024-point Fast Fourier Transformer (FFT) for transformation, which detects the intensity of the distribution of the input signal at each instantaneous sampling point in the frequency domain of the main spectral component Send to psychoacoustic model control unit. According to the statistical results of auditory psychoacoustic measurements, a psychoacoustic control comparison table can be concluded, and the control unit can be made according to this table, and the unit circuit can collectively reflect the threshold characteristics and masking characteristics of the human ear.
The quantized data of 32 sub-bands has been compressed, and auxiliary information such as scale factor and bit allocation information must be added to a bit stream formatting unit to encode into two levels of audio coding signals. It contains not only the sound numbers of 32 sub-bands, but also the bit allocation data corresponding to these numbers and the strength and weakness scale factors of the data in different frequency bands. When the data is to be decoded in the future, the sound signal can be restored according to the data of each sub-band, as well as the code bit allocation and the strength and weakness ratio during compression. When performing inverse quantization, refer to the compression program to restore.
It can be seen that the compression coding of sound is similar to image processing, but also undergoes transformation, quantization, code point compression and other processing processes. It uses many mathematical models and statistical data of psychoacoustic measurement. It also processes 32 subbands and signals at various levels. Each has a different sampling rate. The actual psychological hearing model and timely processing control process is very complicated. The details of these algorithms have been solidified in the decoding chip by hardware, and these contents cannot be changed any more.
3. Synchronization of sound and image There are many different compression methods for image and sound signals. The amount of image data is much larger than the amount of sound data, and the data bit rates transmitted by the two are very different. Only one audio data packet is transmitted after every 14 to 15 video data packets are transmitted, and the content of playing sound and images must be well synchronized, otherwise the unified effect of audio-visual will not be guaranteed.
In order to achieve sound image synchronization, MPEG-1 uses an independent system clock (referred to as STC) as a reference for encoding, and divides the image and sound data into many playback units. For example, the image is divided into several frames, and the sound is divided into several paragraphs. During data encoding, a presentation time stamp (PTS) or a decoding time stamp (DTS) is added in front of each playback unit. When these time marks appear, it means that the previous playback unit has ended and a new image and sound playback unit starts immediately. When the same picture unit and sound unit corresponding to each other are played, they can be synchronized with each other.
In order to make the whole system have a common clock reference when the clock is being encoded and played back, the concept of the system reference clock SCR is introduced. The system reference clock is a real-time clock, and its value represents the actual playing time of the sound image. Use it as a reference to ensure that the transmission time of the sound image signal remains consistent. The real-time clock SCR must be consistent with the real time in life, and its accuracy is required to be very high, otherwise the phenomenon that both the sound and the image are broadcast fast or slow may occur. In order to make the SCR time reference stable and accurate, MPEG-1 uses the system clock frequency SCF, which is used as a reference basis for timing information. The frequency of the SCF system clock is 90KHz, and the frequency error is 90KHz ± 4.5KHz. The sound image signal is based on SCF, and other timing signals SCR, PTS and DTS are also based on it.
3. Other MPEG standard audio encoders
1. MPEG-2 audio coding block diagram
MPEG-1 is to deal with two-channel stereo signals, while MPEG-2 is to deal with 5-channel (or 7-channel) surround stereo signals, its playback effect is more realistic.
Figure 2.3.3 is a block diagram of MPEG-2 audio encoding. It inputs 5-channel audio signals that are independent of each other, with front left and right main channels (L, R), front center channel (C), and rear left and right surround channels (LS, RS) . After the analog-to-digital conversion of each sound source, it first enters the subband filter, and each channel must be divided into 32 subbands, and the bandwidth of each subband is 750 Hz. In order to be compatible with encoding methods such as MPEG-1, ordinary two-channel stereo and surround analog stereo, the original stereo channels encoded by MPEG-1 can be expanded to multi-channel, which should include all 5 channels of information, for which matrix transformation Circuit. This circuit can generate compatible traditional stereo signals LO, RO, as well as "emphasized" left, center, right, left surround, and right surround sound signals (a total of 5 channels). The reason for "emphasis" processing of 5 surround sound signals: when calculating compatible stereo signals (LO, RO), in order to prevent overload, all signals have been attenuated before encoding, and they can be distorted after emphasis; in addition , Matrix transformation also includes attenuation factor and similar phase shift processing.
The original signal of the encoder is 5 channels, and the input channel is 5. After matrix conversion processing, 7 kinds of sound signals are generated. The channel selection circuit should be set up, which can reasonably select and process 7 signals according to needs. The processing process depends on the process of matrix solution and the distribution information of the transmission channel; reasonable channel selection is helpful to reduce noise interference caused by man-made noise processing. In addition, a multi-channel prediction calculation circuit is provided to reduce the redundancy between channels. When performing multi-channel prediction, the compatible signals LO and RO in the transmission channel can be calculated from MPEG-1 data. According to the physiological and acoustic basis of the human ear
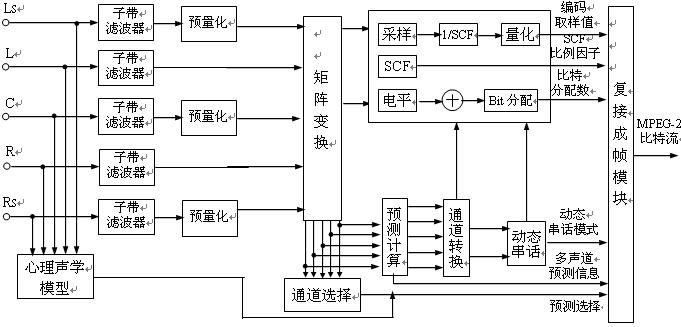
Basically, a dynamic crosstalk circuit is set in the latter stage, which can improve the sound quality under the condition of a given bit, or reduce the bit rate under the premise of requiring sound quality. But setting this circuit increases the complexity of the MPEG-2 decoder.
A variety of information is generated by the encoder, mainly including encoded sample values, scale factors, bit allocation data, dynamic crosstalk mode, multi-channel prediction information, channel prediction selection signals, etc. The information is passed to the multiplexing framing module circuit, Finally, the compressed encoded signal is output in the form of MPEG-2 bit stream.
The MPEG-2 decoder is basically the reverse process of the encoder, its circuit structure is simpler, and the amount of calculation is smaller. The decoder's decoding conversion matrix can output 5 signals, which are then processed by the 32-frequency sub-band filter, and can output LS, L, C, R, RS signals; The front stereo LO and RO can be obtained, and a total of 7 audio signals can be output.
2. MPEG-4 audio decoding
MPEG-4 audio coding, like MPEG-4 video coding, has many features and functions, such as scalability, limited time audio stream, audio change / time scale change, editability, delay, etc. It has superior interactive performance and high compression ratio. Not only can it use the grading method to edit language and music, but it can also solve the problem of synthesized language and music. It will become a major format in the multimedia world and will become a "all-round" system.
Through MPEG-4 audio coding, various audio contents can be stored and transmitted. It has high-quality audio signals (mono, stereo and multi-channel). It uses low bit rate encoding, and the sound playback quality is very high. It can transmit broadband language signals (such as 7KHz wide voice), and can also transmit narrow bandwidth language signals (such as long-distance calls). It can transmit and make various understandable voice signals. You can synthesize languages, such as text conversion based on phonemes or other symbols; you can also synthesize audio, such as supporting music description languages.
4. Dolby AC-3 technology
1. What is Dolby AC-3
Based on Dolby Pro Logic surround sound technology, in 1990 Dolby Co., Ltd. and Japan Pioneer Corporation adopted advanced digital compression technology to launch a novel fully digital Dolby Digital surround sound system. It enables more information in multi-channel signals to be compressed into two channels, and calls this system AC-3. AC is an acronym for English "Audio Sensing Encoding System". The AC-3 technology was first applied to movie theaters and later into ordinary families.
The Dolby AC-3 system sets up 6 completely independent channels, namely the full-band left, center, right, left surround and right surround channels, plus a subwoofer channel. Due to the structure of such a channel, the AC-3 system is also called 5.1 channel.
2. The basic principle of Dolby AC-3
(1) Applying the auditory masking effect to develop an adaptive coding system
The theoretical basis of AC-3 technology is also to use the auditory threshold and masking effect in psychoacoustics, but the specific technology is different from the MPEG standard.
When data processing is performed on audio signals, data compression must be performed to ignore data information that has no or little use. To this end, auditory thresholds and masking laws can be applied to omit those redundant data information. In addition to the above-mentioned acoustic principles, Dolby also used the Dolby noise reduction technology it possessed to develop a digital "adaptive coding" system. This is an adaptive coding system that is extremely selective and capable of suppressing noise. According to the basic principles of acoustic psychology, Dolby maintains a quiet state when no music signal is input; when a music signal is input, it analyzes and decomposes the complex audio signal, masks the noise with a stronger signal, and removes the auditory limit, Or because the frequency is similar and the volume is low, after this processing method, the data information that needs to be processed can be greatly reduced. The hearing range of the human ear is 20Hz-20KHz. In such a wide frequency band, the hearing sensitivity of the human ear to different frequencies is very different. According to this characteristic, Dolby AC-3 divides the audio channels of each channel into many narrow frequency bands of different sizes, and each sub-band is close to the width of the critical frequency band of the human ear, retains effective audio, and tightens different noise frequencies. Encode with each channel signal, that is, encoding noise can only exist in the frequency band of the encoded audio signal. In this way, the coding noise can be more steeply filtered out, and the coding noise of the redundant signal and no audio signal in the frequency band can be reduced or removed, while the useful audio signal is retained. The AC-3 system accurately uses the masking effect and the "common bit group" design method, which greatly improves the data compression efficiency and has a very high level of sound quality. The bit rate of the system is allocated to each narrow frequency band according to the needs of individual spectrum or the dynamic status of the audio source. It has a built-in auditory masking program that allows the encoder to change its frequency sensitivity and time resolution to ensure Sufficient bits are used to mask the noise and record the music signal well.
In order to efficiently use limited information transmission media (optical discs, films, etc.), it uses the auditory characteristics of the human ear when compressing audio signals like other compression systems, and combines the coefficients of certain channels according to the specific conditions at the time ( These channel coefficients reflect the energy level of that frequency band) in order to increase the compression rate. Not all channels can be combined in this way. The encoder can automatically determine and adjust according to the information characteristics of each channel. Only similar channels can be mixed together. If the compression ratio is not required to be high, it does not need to be combined. In general, the higher the starting frequency of the merger, the better the sound quality, but the higher the data transmission rate. When the sampling frequency is 48KHz, the combined starting frequency should be 3.42MHz; if the sampling frequency is 44.1KHz, the starting frequency should be 3.14MHz. If the hardware and software are properly matched, the sound quality of AC-3 can reach or approach the level of CD records.
(2) Simple block diagram of Dolby AC-3 decoder
The input signal of the AC-3 decoder is a set of spectrum signals, which is obtained by time-frequency conversion of the time-domain signal PCM data. The spectrum data stream is divided into an exponent part and a mantissa part. The exponent part is encoded in a differential manner. The encoded exponent represents the entire signal spectrum and can be used as a parameter of the spectrum envelope. The mantissa part is quantized according to the result of bit allocation. Therefore, the quantization mantissa and the spectrum envelope form the main information of the AC-3 code stream, together with other auxiliary signals (such as bit allocation, etc.) constitute the AC-3 bit stream.
Figure 2.3.4 is the decoding block diagram of AC-3 system, which is the reverse process of AC-3 encoding. The AC-3 bit stream first enters the buffer stage, and then uses the frame as the processing unit to perform error correction. After error correction, the fixed data (exponential data, matching coefficients, pattern symbols, etc.) in the bit stream is decoded to make the data bits The stream is restored to the original bit allocation. 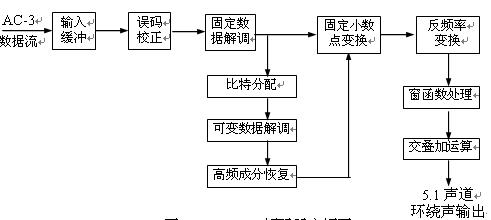
Then, the data signal is divided into two channels. In one way, after restoring the bitstream to the original bit allocation, determine the size of the quantization in the mantissa, and then decode the variable data in the bitstream; then restore the high-frequency components to prepare for the inverse frequency transformation. Finally, the exponent data and the mantissa data are merged and converted into fixed decimal point data, and then frequency transformation is performed on it to obtain time axis data. Data signals that have been restored to the time domain require window processing and overlap addition to obtain the 5.1 surround channel output signal.
3. Features of Dolby AC-3
(1) Configure 5.1 channel to decode the input audio signal and output 5.1 channel signal, including 3 front channels (L, C, R), and 2 rear surround channels (LS, RS), they are independent of each other, and the frequency response width is the full acoustic frequency domain, namely 20Hz-20KHz (± 0.5dB) and 3Hz-20.3KHz (-3dB), the frequency response of each channel is very wide. At present, the Dolby directional logic surround sound system, which is widely used in audio systems, cannot be compared with the Dolby AC-3 frequency bandwidth. In addition, the Dolby Pro Logic surround sound system is actually a 4-channel system, namely front left, center, right and rear surround sound. Its surround sound is actually mono surround sound and two rear surround channels To replay the common sound signal, the two channels are connected in parallel or even in series; the frequency response of the surround sound is limited to the range of 100Hz-7KHz; in addition, it does not set an independent subwoofer channel, it is composed of the front left, The right channel separates the 20Hz-120Hz subwoofer to replay the subwoofer with a shocking effect. The AC-3 system is equipped with an independent ultra-low channel with a frequency response of 20Hz-120HZ (± 0.5dB) and 3Hz-121Hz (-3dB). The volume of the ultra-low speakers is required to be 10dB higher than that of other channels. Shocking low effect.
(2) Each channel is fully digitized and independent of each other
The AC-3 channels carry different signals independently of each other and are fully digitized audio signals. The sampling frequency is 32, 44.1 or 48KHz, the data transmission volume is 32kb / s-640kb / s per channel, the typical value is 384kb / s in 5.1 channel mode, and the typical value is 192kb / s in dual channel mode. After digital processing, the frequency of the five main channels is compressed within the range of 20Hz-20KHz.
(3) The 5.1 channel can be compressed and output. Because there is a "guidance signal" for each program mode (mono, stereo, surround sound, etc.) in the "bit stream" of AC-3, AC-3 can be automatically Point out the program mode for the user. It can compress 5.1 channel signals into two channels for recording conventional VHS video tapes, or as an input program source for Dolby surround sound, so as to be compatible with it, it can even compress 5.1 channel signals into mono output . In short, AC-3 can output 5.1-channel Dolby surround sound, mixed 4-channel Dolby surround sound, two-channel stereo and mono. The compressed 5.1-channel data occupies a relatively narrow frequency band. For example, it can encode AC-3 data and output AC-3 RF signals within the bandwidth occupied by the FM modulated right channel of the LD player. The center frequency is taken at 2.88MHz, and the AC-3 coded signal with a frequency of 2.88MHz can be taken from the original analog output right channel of the LD. Therefore, all the contents of 5.1 channels can be accommodated in the original analog channel.
(4) After the sound time calibration, the sound effect is extremely ideal. Dolby AC-3 passes all the channels through the "time calibration" technology, so that the sound of each speaker seems to be the same distance from the listener to produce better sound effects. The surround sound effect is not only a clear localization of the front, back, left and right sound sources, but also the clear sound fields above and below.
What is 5G CPE?
Definition of 5G CPE
CPE stands for Customer Premise Equipment. The so-called front end refers to the equipment in front of the customer's terminal equipment. When we use Wi-Fi, if the distance is far, or there are more rooms, it is easy to appear signal blind spots, resulting in mobile phones or ipads or computers can not receive Wi-Fi signals. The CPE can relay the Wi-Fi signal twice to extend the coverage of Wi-Fi.
What are the benefits of CPE?
Through the following comparison table, it is not difficult to understand the technical advantages of CPE products:
* Currently, the global 5G FWA service is mainly in the Sub-6GHz band, with only the United States and Italy supporting the millimeter wave band.
* 5G CPE integrates the low cost of Wi-Fi and the large bandwidth of 5G, combining the advantages of the two to form a strong complement to traditional fiber broadband.
The relationship between 5G, FWA and CPE
It can be said that FWA (Fixed Wireless Access) will be the most down-to-earth application of 5G technology. FWA business plays a key role in enabling "connecting the unconnected." FWA is a low-cost, easy-to-deploy flexible broadband solution. Compared with wired access technology, FWA has been an ideal choice for deploying broadband in many countries and regions because it does not need to obtain rights of way, dig trenches and bury cables, and drill holes through walls. The development of 5G technology is further promoting the development of FWA.
FWA services (including 4G and 5G) have reached 100 million users. FWA is no longer a niche service; The FWA industry as a whole has been supported by numerous suppliers. Why is that? In the 5G era, 5G CPE receives 5G signals from operator base stations and then converts them into Wi-Fi signals or wired signals to allow more local devices to get online. For operators, the initial user penetration rate of 5G is low, and the investment is difficult to realize quickly; The CPE business can use the idle network to increase revenue for operators, so major operators vigorously promote the development of 5G CPE.
FWA services can be used for both home (To C) and business (To B), and customers have different requirements for CPE devices when using FWA services in different application environments, resulting in consumer grade 5G CPE and industrial grade 5G CPE (similar to home routers and industrial routers).
In 2020, the global market size of 5G CPE will reach 3 million units, and it is expected that in the next five years, the market size of 5G CPE will maintain a compound growth rate of more than 100%, reaching 120 million units in 2025, with a market value of 60 billion yuan. As an important market for 5G CPE, China's 5G CPE market size will reach 1.5 million units in 2020 and is expected to reach 80 million units in 2025, with a market value of 27 billion yuan.
The difference between 5G CPE and other devices
CPE can support a large number of mobile terminals that access the Internet at the same time, and the device can be directly inserted with a SIM card to receive mobile signals. CPE can be widely used in rural areas, cities, hospitals, units, factories, communities and other wireless network access, can save the cost of laying wired networks.
A Router is a hardware device that connects two or more networks, acts as a gateway between networks, and is the main node device of the Internet. Routers use routes to determine the forwarding of data. If it is a home router, it does not support a SIM card slot, and can only receive signals by connecting to optical fiber or cable and then convert it into WI-FI to provide a certain number (several) of terminal devices to surf the Internet.
Industrial 5G CPE is equivalent to 5G industrial routers, and the technology of the two is not very different. On the one hand, the industrial 5G CPE converts 5G network signals into WiFi signals for transmission, and on the other hand, the data received by the WiFi network is converted into 5G network signals for uploading. In addition, industrial 5G CPE generally supports routing functions.
5G CPE trends
According to a research report, after evaluating the products of some mainstream 5G CPE suppliers, many institutions believe that the development of 5G CPE products will continue in two aspects: one is to support mmWave and Sub-6 GHz at the same time; Second, the design will pay attention to humanized operation and installation. The industry development trend will accelerate the demand for 5G in the medical, education and manufacturing industries due to the epidemic, and 5G FWA will promote global 5G CPE shipments.
Wireless Cpe,4G Cat6 Cpe,4G Mifi,4G Ufi
Shenzhen MovingComm Technology Co., Ltd. , https://www.mcrouters.com