Abstract: Traditionally, if we want to make a computer work, we give it a bunch of instructions, and then it follows this instruction step by step. There are results, very clear. However, this method does not work in machine learning. Machine learning does not accept the instructions you enter at all. Instead, it accepts the data you entered!
In this article, I will give an overview of machine learning. The purpose of this article is to enable anyone who does not even understand machine learning to understand machine learning and to get started with relevant practices. This document can also be considered as an extra chapter of EasyPR development. From here, we must understand the machine learning in order to further introduce the core of EasyPR. Of course, this article also faces the general readers and will not have relevant prerequisite requirements for reading.
Before entering the topic, I think that there may be a doubt in the reader's mind: what importance is machine learning, so that you want to read this very long article?
I do not directly answer this question before. On the contrary, I would like to invite everyone to look at the two plans.
The following figure is Figure 1:

Figure 1 Marriage between executives in the machine learning world and predators in the Internet community
The three people on this map are the leaders of today's machine learning community. In the middle is Geoffrey Hinton, a professor at the University of Toronto, Canada, who is now head of the Google Brain. On the right is Yann LeCun, a professor at New York University and now director of the Facebook Artificial Intelligence Lab. The people on the left are familiar with Andrew Ng, whose Chinese name is Wu Enda, an associate professor at Stanford University, and who is now the head of the “Baidu Brain†and Baidu’s chief scientist. These three are the hottest players in the industry. They are being hired by the Internet giants to see their importance. And their research direction is all subclasses of machine learning - deep learning.
The following figure is Figure 2:

Figure 2 Voice Assistant product
What is depicted on this picture? Cortana, the voice assistant on Windows Phone, was named after the assistant chief of the Sergeant in Halo. Compared to other competitors, Microsoft launched the service very late. What is the core technology behind Cortana and why does it understand human speech? In fact, this technology is exactly machine learning. Machine learning is a key technology for all human voice assistant products (including Apple's siri and Google's Now) to interact with people.
Through the above two figures, I believe we can see that machine learning seems to be a very important technology with many unknown features. Learning it seems like an interesting task. In fact, learning machine learning can not only help us understand the latest trends in the Internet community, but also know the implementation technologies that accompany our convenience services.
text
What is the machine learning and why it can have such a great magic, these questions are exactly what this article answers. At the same time, this article is called "talking from machine learning", so it will introduce all the contents related to machine learning, including disciplines (such as data mining, computer vision, etc.), algorithms (neural networks, svm) and so on. The main contents of this article are as follows:
A story shows what is machine learning
Definition of machine learning
The scope of machine learning
Machine learning methods
Machine Learning Applications - Big Data
Subclasses of Machine Learning - Deep Learning
Machine Learning Parent Class – Artificial Intelligence
Machine Learning Thinking - Computer Subconscious
to sum up
postscript
1. A story explains what is machine learning
The term machine learning is puzzling. First of all, it is the literal translation of the English name Machine Learning (ML for short). In computing, Machine generally refers to computers. The name uses anthropomorphic tricks to show that this technology is a technique that allows the machine to "learn". But how can a computer "learn" when it is dead?
Traditionally, if we want to make the computer work, we give it a bunch of instructions, and then it follows this directive step by step. There are results, very clear. However, this method does not work in machine learning. Machine learning does not accept the instructions you enter at all. Instead, it accepts the data you enter! In other words, machine learning is a way for computers to use data rather than instructions to perform various tasks.
This sounds incredible, but the result is very feasible. The idea of ​​"statistics" will always be accompanied when you learn the concepts related to "machine learning". The notion of relevance, not causation, will be the core concept that supports machine learning to work. You will subvert the fundamental idea of ​​causality that has been established in all your previous programs.
Below I use a story to simply clarify what is machine learning. This story is more suitable for use as a concept of elucidation. Here, this story has not been unfolded, but the relevant content and core exist. If you want to briefly understand what machine learning is, then reading this story is enough. If you want to learn more about machine learning and the contemporary technologies associated with it, then please continue to look down and have more rich content behind.
This example comes from my real life experience. When I was thinking about this problem, I suddenly discovered that its process could be extended to a complete machine learning process. So I decided to use this example as the beginning of all the introduction. This story is called "waiting for someone else's question."
I believe that everyone has to meet someone else and wait for others to experience it. In reality, not everyone is so punctual, so when you come across someone who is late for love, your time is inevitably wasted. I have encountered such an example.
For one of my friend Xiao Y, he is not so punctual. The most common manifestation is that he is often late. When I once had an appointment with him at 3 o'clock to meet someone at McDonald's, the moment I went out I suddenly thought of a question: Is it appropriate for me to start now? Will I spend 30 minutes waiting for him after I arrive? I decided to take a strategy to solve this problem.
There are several ways to solve this problem. The first method is to use knowledge: I search for knowledge that can solve this problem. But unfortunately, no one will pass on the question of how to wait for people as knowledge, so I cannot find the existing knowledge to solve this problem. The second method is to ask others: I ask other people the ability to solve this problem.
But the same, no one can answer this question, because no one may run into the same situation with me. The third method is the normative method: I asked my own heart, have I established any criteria to face this problem? For example, I will arrive on time, regardless of other people. But I am not a rigid person. I have not established such a rule.
In fact, I believe that one method is more suitable than the above three. I relived my experience of meeting with Xiaoyin in my mind to see what proportion of the number of appointments with him was late. And I use this to predict his chances of being late.
If this value exceeds a certain limit in my heart, then I choose to wait for a while before starting. Suppose I'm about 5 times with Xiaoyue and the number of times he's late is 1, then he's 80% on time. The threshold in my mind is 70%. I think this time Little Y shouldn't be late, so I'm on time. Go out.
If Xiao Y occupies 4 times out of 5 times late, that is, he is 20% on time, because this value is lower than my threshold, so I chose to postpone the time for going out. This method is also called empirical method from the perspective of its utilization. In the process of thinking about empirical methods, I actually used all the same data in the past. Therefore, it can also be called judgment based on data.
The judgment based on the data is fundamentally consistent with the idea of ​​machine learning.
In the process of thinking just now, I only considered the attribute of "frequency". In real machine learning, this may not be an application. The general machine learning model considers at least two quantities: one is the dependent variable, which is the result we want to predict, and in this case it is the judgement of whether Little Y is late or not.
The other is the independent variable, which is the amount used to predict whether Y is late. Suppose I took time as an independent variable. For example, I found that all Y's late days were basically Friday, but he was basically not late for non-Friday. So I can build a model to simulate the probability that Little Y is late or whether the day is a Friday. See below:
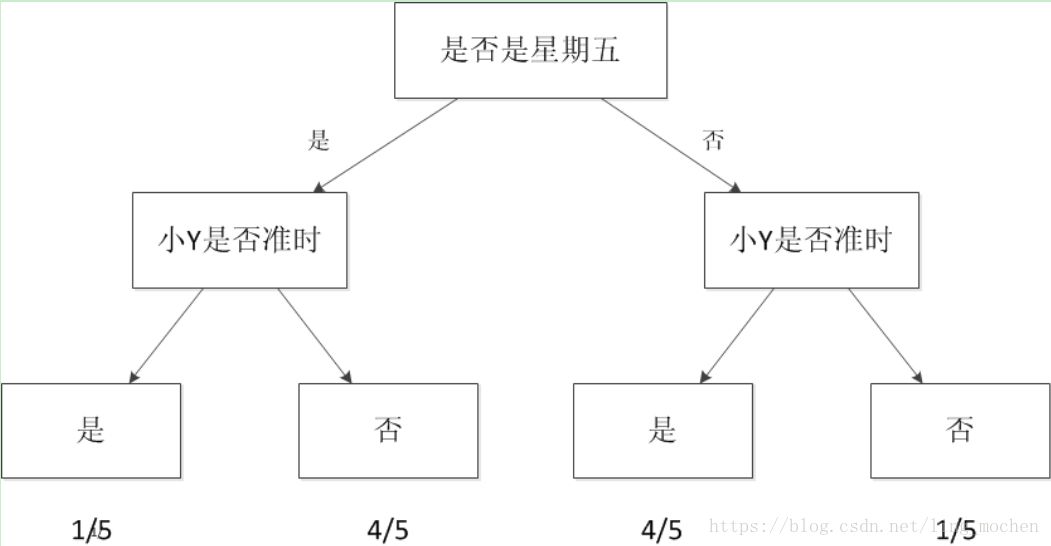
Figure 3 Decision tree model
Such a graph is the simplest machine learning model, called a decision tree.
When we consider only one independent variable, the situation is simpler. If we increase our argument by one more. For example, when the young Y is late in part, it is when he drives in (you can think of him as driving a bad smell, or the road is blocked). So I can consider this information in association. Create a more complex model that contains two independent variables and one dependent variable.
Even more complicated, Xiao Y's lateness and weather also have certain reasons. For example, when it rains, I need to consider three independent variables.
If I want to be able to predict the specific time when Y is late, I can establish a model with each time he arrives late with the size of the rain and the previously considered independent variables. So my model can predict the value, for example, he will probably be a few minutes late. This will help me better plan my time out. In this situation, the decision tree is not well supported because the decision tree can only predict discrete values. We can use the linear regression method introduced in Section 2 to build this model.
If I give these computers the process of modeling. For example, input all the independent variables and dependent variables, and let the computer help me to generate a model. At the same time, let the computer give me a suggestion based on my current situation, whether or not I need to delay the door. Then the process of computers performing these auxiliary decisions is the process of machine learning.
The machine learning method is a method in which a computer uses existing data (experience) to obtain a certain model (a pattern of lateness) and uses the model to predict the future (whether it is late).
From the above analysis, it can be seen that machine learning is similar to the empirical process of human thinking, but it can consider more situations and perform more complex calculations. In fact, one of the main purposes of machine learning is to transform the process of human thinking and inducting experience into the process of computer computing and computing the model. Computer-derived models can solve many flexible and complex problems in a human-like manner.
Below, I will begin a formal introduction to machine learning, including definitions, scope, methods, applications, etc., all of which are included.
2. The definition of machine learning
Broadly speaking, machine learning is a method that gives the machine the ability to learn so that it can perform functions that direct programming cannot accomplish. But in a practical sense, machine learning is a method of training a model by using data, and then using model prediction.
Let us look at an example concretely.
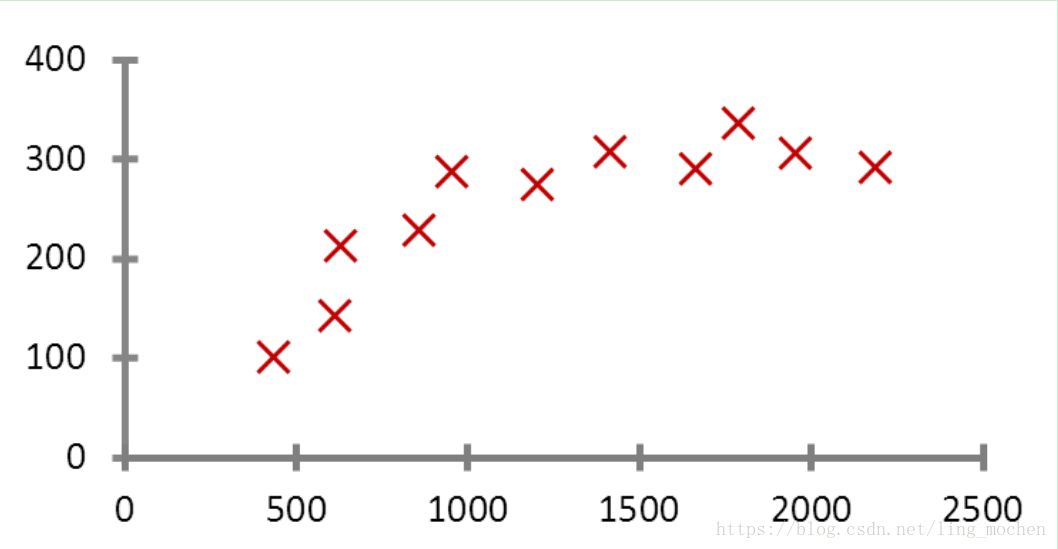
Figure 4 Example of house prices
Take the house of national topics. Now that I have a house in my hand that needs to be sold, what price should I label it? The area of ​​the house is 100 square meters, the price is 1 million, 1.2 million, or 1.4 million?
Obviously, I hope to get some rules of house prices and area. So how do I get this rule? Do you use the average house price data in the newspaper? Or reference other people's area is similar? Either way, it does not seem to be too reliable.
I now hope to get a reasonable and most able to reflect the law of the relationship between area and house prices. So I investigated some houses that were similar to my room type and got a set of data. This set of data includes the size and price of large and small houses. If I can find out the rules of area and price from this set of data, then I can get the price of the house.
The search for the law is very simple, fitting a straight line, letting it “cross†all the points, and the distance from each point is as small as possible.
Through this straight line, I obtained a law that best reflects the law of house prices and areas. This line is also a function of the following formula:
Rates = area* a + b
Both a and b in the above are linear parameters. After obtaining these parameters, I can calculate the price of the house.
Assuming a = 0.75, b = 50, then house prices = 100 * 0.75 + 50 = 1.25 million. This result is different from the 1 million, 1.2 million, and 1.4 million listed in my previous list. Since this line takes into account most of the situations, it is a most reasonable prediction in the sense of “statisticsâ€.
Two pieces of information were revealed during the solution:
1. The house price model is based on the type of function fitted. If it is a straight line, then the fitted linear equation. If it is another type of line, such as a parabola, then the parabolic equation is fitted. There are many algorithms for machine learning. Some powerful algorithms can fit complex nonlinear models to reflect situations that are not expressible by straight lines.
2. If I have more data, the more patterns my model can think about, the better predictive the new situation may be. This is a manifestation of the "data is king" thought in the machine learning world. In general (not absolute), the more data, the better the model predictions generated by the last machine learning.
Through my process of fitting a straight line, we can make a complete review of the machine learning process. First of all, we need to store historical data in the computer. Next, we process these data through machine learning algorithms. This process is called “training†in machine learning. The results of the processing can be used by us to predict new data. This result is generally called “modelâ€. The process of predicting new data is called "prediction" in machine learning. "Training" and "prediction" are two processes of machine learning, "model" is the intermediate output of the process, "training" produces "model", and "model" guides "prediction."
Let us compare the process of machine learning with the process of human induction of historical experience.
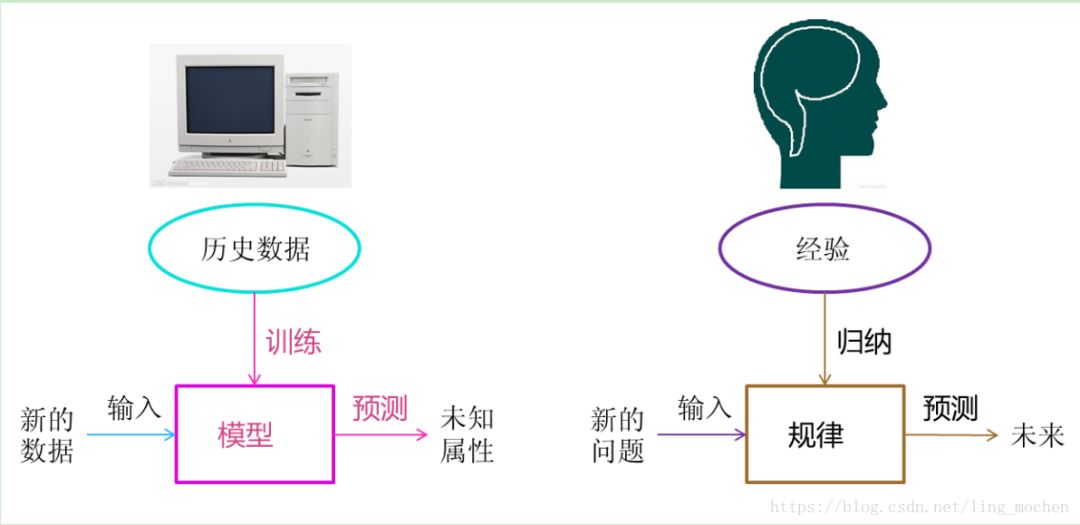
Figure 5 Analogy between machine learning and human thinking
Humanity has accumulated a lot of history and experience in the process of growth and life. Humans regularly "generalize" these experiences and obtain "laws" of life. When humans encounter unknown problems or need to "guess" the future, humans use these "rules" to "guess" unknown problems and the future to guide their lives and work.
The "training" and "prediction" processes in machine learning can correspond to the "induction" and "speculation" processes of humans. Through this correspondence, we can find that the idea of ​​machine learning is not complicated, but merely a simulation of human learning and growth in life. Since machine learning is not based on the result of programming, its processing is not causal logic, but rather a conclusion drawn from inductive thinking.
This can also be a reminder of why humans have to learn history. History is actually a summary of mankind's past experience. There is a saying well. "History is often different, but history is always surprisingly similar." By learning history, we can sum up the laws of life and the country from history and guide our next steps. This is of great value. Some people in modern times have overlooked the original value of history, but have used it as a means of promoting merit. This is actually a misuse of the true value of history.
3. The scope of machine learning
Although the above illustrates what machine learning is, it does not give the scope of machine learning.
In fact, machine learning has a deep connection with pattern recognition, statistical learning, data mining, computer vision, speech recognition, and natural language processing.
In terms of scope, machine learning is similar to pattern recognition, statistical learning, and data mining. At the same time, the combination of machine learning and processing techniques in other fields has formed interdisciplinary subjects such as computer vision, speech recognition, and natural language processing. Therefore, generally speaking, data mining can be equivalent to machine learning.
At the same time, what we usually call machine learning applications should be universal, not only limited to structured data, but also applications such as images and audio.
The introduction of these related fields in machine learning in this section helps us clarify the application scenarios and research scope of machine learning, and better understand the underlying algorithms and application layers.
The following figure shows some of the relevant areas of discipline and research areas involved in machine learning.

Figure 6 Machine Learning and Related Subjects
Pattern recognition
Pattern recognition = machine learning. The main difference between the two is that the former is a concept developed from the industrial sector, while the latter is mainly derived from the computer science. In the famous "Pattern Recognition And Machine Learning" book, Christopher M. Bishop said at the beginning: "Pattern recognition originates from industry, and machine learning comes from computer science. However, activities in them can be viewed. For the two aspects of the same field, and in the past 10 years, they have all made considerable progress."
Data mining
Data Mining = Machine Learning + Database. The concept of data mining in recent years is really familiar. Almost equal to hype. But all that data mining will boast about how data mining, such as digging out gold from data, and turning waste data into value, and so on. However, although I might mine gold, I may also mine "stone."
The meaning of this statement is that data mining is only a way of thinking, telling us that we should try to dig out the data from the data, but not every data can excavate gold, so do not be mythical. A system will never become omnipotent because of a data mining module (this is what IBM most likes to boast about). On the contrary, a person with data mining thinking is the key, and he must also have profound data The understanding that it is possible to derive from the data model to guide the improvement of the business. Most algorithms in data mining are optimizations of machine learning algorithms in the database.
Statistical learning
Statistical learning is approximately equal to machine learning. Statistical learning is a highly overlapping discipline with machine learning. Because most of the methods in machine learning come from statistics, it is even believed that the development of statistics has promoted the prosperity of machine learning. For example, the well-known support vector machine algorithm is derived from the statistics department.
But to a certain extent, there is a difference between the two. The difference is that statistical learners are focusing on the development and optimization of statistical models and partial mathematics, while machine learners are more concerned with solving problems and practicing more. Machine learning researchers will focus on improving the efficiency and accuracy of learning algorithms performed on computers.
Computer vision
Computer Vision = Image Processing + Machine Learning. Image processing technology is used to process the image as an input into a machine learning model, and machine learning is responsible for identifying the relevant pattern from the image. There are many applications related to computer vision, such as Baidu maps, handwritten character recognition, license plate recognition, and so on. This field is a very promising application, and it is also a popular research direction. With the development of deep learning in the new field of machine learning, the effect of computer image recognition has been greatly promoted. Therefore, the future of computer vision development is immeasurable.
Speech Recognition
Speech recognition = speech processing + machine learning. Speech recognition is the combination of audio processing technology and machine learning. Speech recognition technology is generally not used alone, but it is generally combined with related technologies of natural language processing. Current related applications include Apple's voice assistant siri.
Natural language processing
Natural language processing = text processing + machine learning. Natural language processing technology is mainly an area where the machine understands human language. In the natural language processing technology, a large number of techniques related to the compilation principle are used, such as lexical analysis, grammar analysis, etc. In addition, at the understanding of this level, semantic understanding, machine learning, and the like are used.
As the only symbol created by human beings, natural language processing has always been the research direction of machine learning. According to Yu Kai, a Baidu machine learning expert, “listening and seeing, plainly speaking, both Arab and American dogs, and only language is unique to humansâ€. How to use machine learning technology to understand natural language has always been the focus of attention in industry and academia.
It can be seen that the machine learning is extended and applied in many fields. The development of machine learning technology has prompted many advancements in the field of intelligence and improved our lives.
4. Machine learning methods
Through the introduction of the previous section we learned about the general scope of machine learning. So how many classic algorithms are there in machine learning? In this section I will briefly introduce the classic representation method in machine learning. The focus of this section is on the intension of these methodologies. The details of mathematics and practice will not be discussed here.
1, the regression algorithm
In most machine learning courses, the regression algorithm is the first one introduced. There are two reasons: First, the regression algorithm is relatively simple, introducing it can make people smoothly migrate from statistics to machine learning. 2. The regression algorithm is the cornerstone behind several powerful algorithms. If you do not understand the regression algorithm, you cannot learn those powerful algorithms. There are two important subclasses of regression algorithms: linear regression and logistic regression.
Linear regression is what we talked about previously. How to fit a straight line to best match all my data? It is generally solved using the "least squares method". The idea of ​​"least squares" is that, assuming that our fitted line represents the true value of the data, the observed data represents the value with the error.
In order to minimize the effect of errors, it is necessary to solve a straight line to minimize the sum of squares of all errors. The least square method converts the optimal problem into the problem of finding the extremum of the function. The mathematical function of the extremum of the function is generally to use the method of finding the derivative 0. However, this approach is not suitable for computers and may not be solved. It may also be too computationally expensive.
The computer science community has a special discipline called "numerical calculations," which are specifically designed to improve the accuracy and efficiency of computers when performing various types of calculations. For example, the famous "gradient descent" and "Newton method" are classical algorithms in numerical calculations and are also very suitable for dealing with the problem of solving function extremes.
The gradient descent method is one of the simplest and most effective methods to solve the regression model. In a strict sense, because of the linear regression factors in both the neural network and the recommendation algorithm, the gradient descent method is also used in the implementation of the following algorithms.
Logistic regression is an algorithm that is very similar to linear regression, but, in essence, the problem type of linear regression processing is inconsistent with logistic regression. Linear regression deals with numerical problems, that is, the final predicted outcome is a number, such as house prices. The logistic regression belongs to the classification algorithm, that is, the logistic regression prediction result is a discrete classification, such as judging whether the mail is spam, and whether the user will click on the advertisement, and so on.
In terms of implementation, logistic regression simply adds a Sigmoid function to the result of the linear regression and converts the numerical result to a probability between 0 and 1 (the image of Sigmoid function is not generally intuitive, you only need to understand The larger the value is, the closer the function gets to 1 and the smaller the value, the closer the function gets to 0). Then we can make a prediction based on this probability. For example, if the probability is greater than 0.5, the email is spam, or if the tumor is malignant. Intuitively speaking, logistic regression is to draw a classification line, see below.
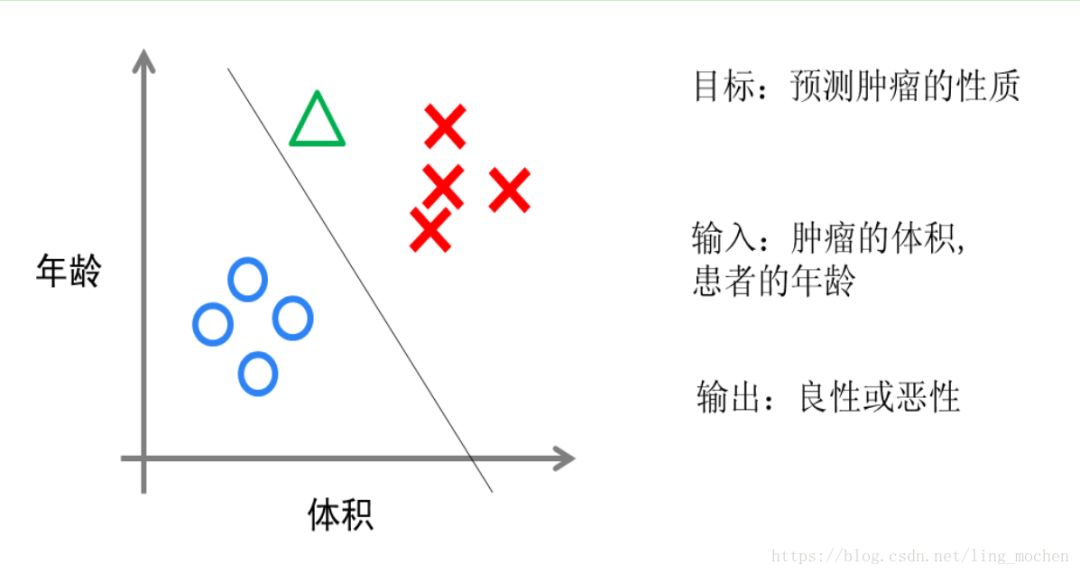
Figure 7 Intuitive explanation of logistic regression
Suppose we have data for a group of cancer patients. Some of these patients' tumors are benign (blue dots in the figure) and some are malignant (red dots in the figure). Here the red and blue color of the tumor can be called the "tag" of the data. At the same time, each data includes two "features": the age of the patient and the size of the tumor. We map these two features and labels to this two-dimensional space, which forms the data of my chart above.
When I have a green dot, should I judge whether the tumor is malignant or benign? According to the red and blue points we have trained a logistic regression model, which is the classification line in the figure. At this time, according to the green point appears on the left side of the classification line, so we judge its label should be red, which means that it is a malignant tumor.
The classification lines drawn by the logistic regression algorithm are basically linear (there are logistic regressions that draw out nonlinear classification lines, but such models are very inefficient when dealing with large amounts of data), which means when two types of When the boundary between the two is not linear, the ability to express logical regression is insufficient. The following two algorithms are the most powerful and important algorithms in the machine learning world and can all fit nonlinear classification lines.
2, neural network
Neural networks (also known as Artificial Neural Networks, ANN) are very popular algorithms in machine learning in the 1980s, but declined in the mid-1990s. Now, with the "deep learning" trend, the neural network is reinstalling and it has become one of the most powerful machine learning algorithms.
The birth of neural networks originated from the study of the working mechanism of the brain. Early bioscientists used neural networks to simulate the brain. Machine learning scholars use neural networks for machine learning experiments and found that both visual and speech recognition are very effective. After the birth of the BP algorithm (a numerical algorithm for accelerating neural network training), the development of neural networks has entered an upsurge. One of the inventors of the BP algorithm was Geoffrey Hinton, a machine learning geek (intermediary in Figure 1).
Specifically, what is the learning mechanism of neural networks? In simple terms, it is decomposition and integration. In the famous Hubel-Wiesel experiment, scholars studied the visual analysis mechanism of cats.
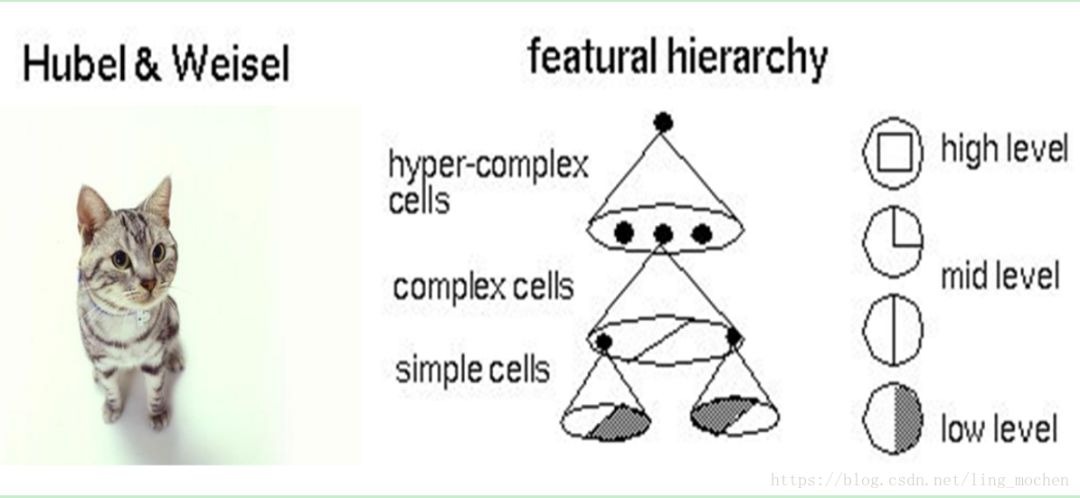
Figure 8 Hubel-Wiesel test and visual mechanism of the brain
For example, a square is broken down into four fold lines into the next layer of visual processing. Each of the four neurons processes a polyline. Each polyline breaks down into two straight lines, each of which is broken down into black and white. Thus, a complex image becomes a large number of details into the neuron, after the neurons are processed and then integrated, and finally it is concluded that the square is seen. This is the mechanism of the visual recognition of the brain and the mechanism of the neural network work.
Let us look at the logical architecture of a simple neural network. In this network, it is divided into input layer, hidden layer, and output layer. The input layer is responsible for receiving the signal, the hidden layer is responsible for the decomposition and processing of the data, and the final result is integrated into the output layer. A circle in each layer represents a processing unit, which can be thought of as simulating a neuron. A number of processing units form a layer, and several layers form a network, which is called "neural network."
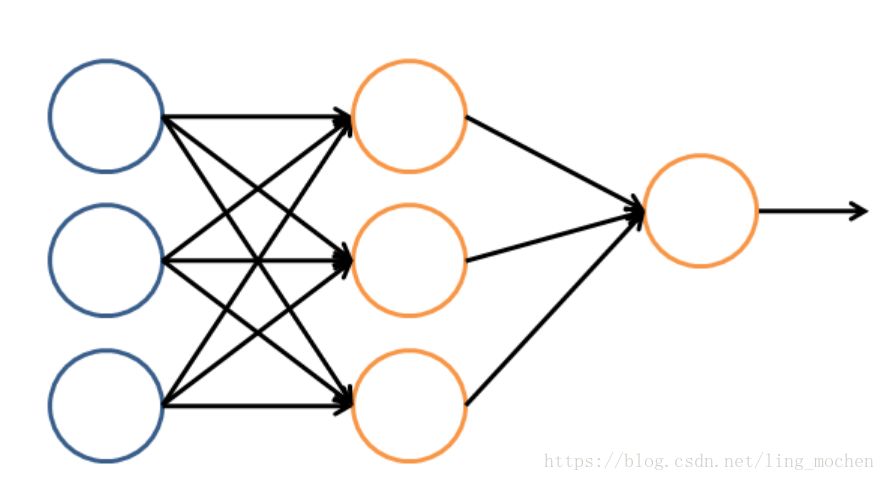
Figure 9 The logical architecture of a neural network
In the neural network, each processing unit is actually a logistic regression model. The logistic regression model receives the input of the upper layer and transfers the prediction result of the model as output to the next level. Through this process, neural networks can complete very complex nonlinear classifications.
The following figure will demonstrate a famous application of neural network in the field of image recognition. This program is called LeNet and it is a neural network based on multiple hidden layers. With LeNet, you can recognize a variety of hand-written numbers, and achieve high recognition accuracy and good robustness.
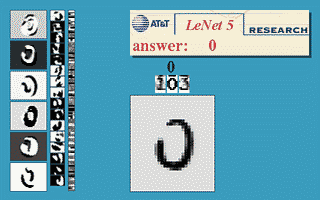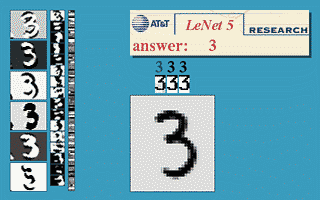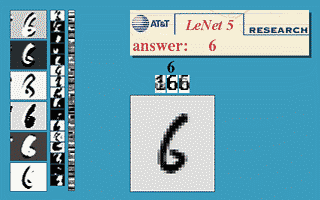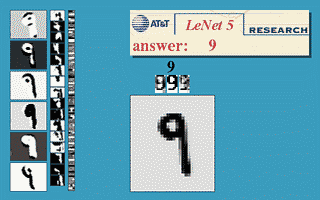
Figure 10 shows the effect of LeNet
An image of the input computer is displayed in the lower right square, and the computer's output is shown in the red square above the word "answer". The three vertical image columns on the left show the output of the three hidden layers in the neural network. It can be seen that as the layers go deeper, the deeper the level of processing details is, the lower the level of processing, for example, the basic processing of layer 3 is already It is detail of line. LeNet's inventor was Yann LeCun, a machine-learning fan introduced in the previous article (Figure 1, right).
In the 1990s, the development of neural networks entered a bottleneck period. The main reason is that despite the acceleration of the BP algorithm, the neural network training process is still very difficult. Therefore, the support vector machine (SVM) algorithm replaced the neural network in the late 1990s.
3, SVM (Support Vector Machine)
Support Vector Machine (SVM) algorithm is a classical algorithm born in the statistical learning world and at the same time it is shining in the machine learning world.
Support vector machine (SVM) algorithm is a kind of enhancement of logistic regression algorithm in a sense: by giving the logistic regression algorithm more strict optimization conditions, SVM algorithm can obtain better classification boundary than logistic regression. However, if there is no certain kind of function technology, the support vector machine algorithm is at best a better linear classification technique.
However, by combining with the Gaussian "nuclear", the support vector machine can express a very complex classification boundary, so as to achieve a good classification effect. "Nuclear" is actually a special kind of function. The most typical feature is that it can map low-dimensional space to high-dimensional space.
For example, the following figure shows:
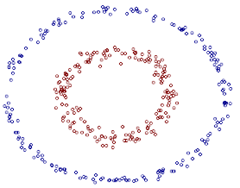
Figure 11 Support Vector Machine Legend
How do we divide a circular boundary in the two-dimensional plane? It may be difficult in a two-dimensional plane, but the "nucleus" can map two-dimensional space to three-dimensional space, and then use a linear plane to achieve a similar effect. In other words, the non-linear classification boundary defined by the two-dimensional plane can be equivalent to the linear classification boundary of the three-dimensional plane. Thus, we can achieve the nonlinear division effect in the two-dimensional plane by simple linear division in three-dimensional space.
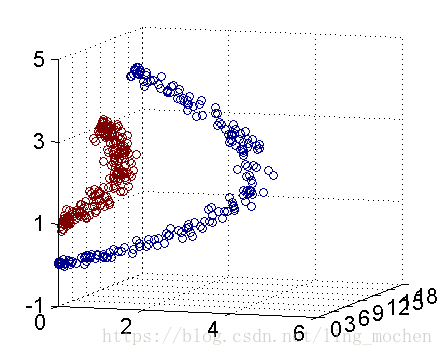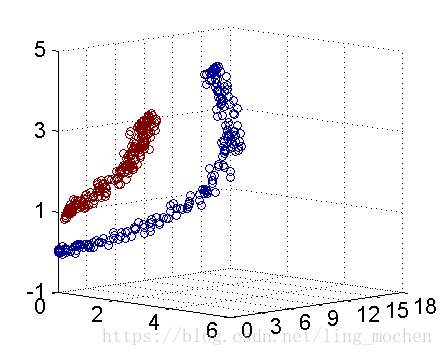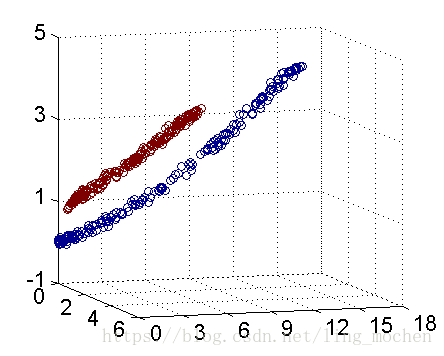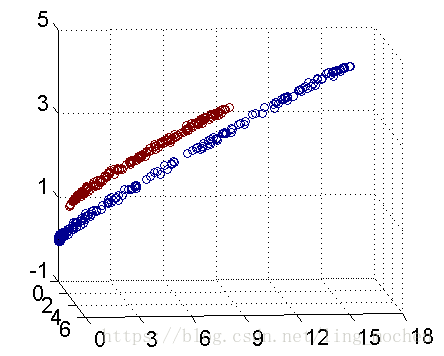
Figure 12 Three-dimensional space cutting
Support vector machines are machine learning algorithms with a very strong mathematical component (relatively, neural networks have biological science components). In the core steps of the algorithm, there is a step to prove that mapping the data from the low dimension to the high dimension does not bring about an increase in the final computational complexity. Thus, through the support vector machine algorithm, it can not only maintain the computational efficiency, but also obtain a very good classification effect. Therefore, support vector machines (SVMs) occupied the most important position in machine learning in the late 1990s, and they basically replaced neural network algorithms. Until now neural networks have re-emerged through deep learning, and a delicate balance shift has taken place between them.
4, clustering algorithm
One of the prominent features of the previous algorithm is that my training data contains tags, and the trained model can predict tags for other unknown data. In the following algorithm, training data is not tagged, and the algorithm's purpose is to infer the tags of these data through training. This kind of algorithm has a general name, namely, unsupervised algorithm (the algorithms with tagged data are supervised). The most typical representative of unsupervised algorithms is the clustering algorithm.
Let us still take a two-dimensional data, a certain data contains two characteristics. I hope to use a clustering algorithm to tag different types of them. What should I do? In simple terms, the clustering algorithm is to calculate the distance in the population and divide the data into multiple groups according to the distance.
The most typical representation in a clustering algorithm is the K-Means algorithm.
5, dimension reduction algorithm
The dimensionality reduction algorithm is also an unsupervised learning algorithm whose main feature is to reduce the data from high dimensional to low dimensional levels. Here, the dimension actually represents the size of the characteristic quantity of the data. For example, the house price includes four characteristics of the length, width, area, and number of rooms of the house, that is, the data with the dimension of 4 dimensions.
It can be seen that the length and width actually overlap with the information represented by the area, such as area = length × width. Through dimensionality reduction algorithm we can remove redundant information and reduce the features to two features of area and number of rooms, that is, compression from 4D data to 2D. Therefore, we reduced the data from high-dimensional to low-dimensional, which not only facilitates representation, but also accelerates computation.
The reduced dimension in the dimension reduction process just mentioned is a level that is visible to the naked eye, and compression at the same time does not bring about loss of information (because the information is redundant).如果肉眼ä¸å¯è§†ï¼Œæˆ–者没有冗余的特å¾ï¼Œé™ç»´ç®—法也能工作,ä¸è¿‡è¿™æ ·ä¼šå¸¦æ¥ä¸€äº›ä¿¡æ¯çš„æŸå¤±ã€‚但是,é™ç»´ç®—法å¯ä»¥ä»Žæ•°å¦ä¸Šè¯æ˜Žï¼Œä»Žé«˜ç»´åŽ‹ç¼©åˆ°çš„低维ä¸æœ€å¤§ç¨‹åº¦åœ°ä¿ç•™äº†æ•°æ®çš„ä¿¡æ¯ã€‚å› æ¤ï¼Œä½¿ç”¨é™ç»´ç®—法ä»ç„¶æœ‰å¾ˆå¤šçš„好处。
é™ç»´ç®—法的主è¦ä½œç”¨æ˜¯åŽ‹ç¼©æ•°æ®ä¸Žæå‡æœºå™¨å¦ä¹ 其他算法的效率。通过é™ç»´ç®—法,å¯ä»¥å°†å…·æœ‰å‡ åƒä¸ªç‰¹å¾çš„æ•°æ®åŽ‹ç¼©è‡³è‹¥å¹²ä¸ªç‰¹å¾ã€‚å¦å¤–,é™ç»´ç®—法的å¦ä¸€ä¸ªå¥½å¤„是数æ®çš„å¯è§†åŒ–,例如将5ç»´çš„æ•°æ®åŽ‹ç¼©è‡³2维,然åŽå¯ä»¥ç”¨äºŒç»´å¹³é¢æ¥å¯è§†ã€‚é™ç»´ç®—法的主è¦ä»£è¡¨æ˜¯PCA算法(å³ä¸»æˆåˆ†åˆ†æžç®—法)。
6ã€æŽ¨è算法
推è算法是目å‰ä¸šç•Œéžå¸¸ç«çš„一ç§ç®—法,在电商界,如亚马逊,天猫,京东ç‰å¾—到了广泛的è¿ç”¨ã€‚推è算法的主è¦ç‰¹å¾å°±æ˜¯å¯ä»¥è‡ªåŠ¨å‘用户推èä»–ä»¬æœ€æ„Ÿå…´è¶£çš„ä¸œè¥¿ï¼Œä»Žè€Œå¢žåŠ è´ä¹°çŽ‡ï¼Œæå‡æ•ˆç›Šã€‚推è算法有两个主è¦çš„类别:
一类是基于物å“内容的推è,是将与用户è´ä¹°çš„内容近似的物å“推èç»™ç”¨æˆ·ï¼Œè¿™æ ·çš„å‰æ是æ¯ä¸ªç‰©å“éƒ½å¾—æœ‰è‹¥å¹²ä¸ªæ ‡ç¾ï¼Œå› æ¤æ‰å¯ä»¥æ‰¾å‡ºä¸Žç”¨æˆ·è´ä¹°ç‰©å“类似的物å“ï¼Œè¿™æ ·æŽ¨è的好处是关è”程度较大,但是由于æ¯ä¸ªç‰©å“都需è¦è´´æ ‡ç¾ï¼Œå› æ¤å·¥ä½œé‡è¾ƒå¤§ã€‚
å¦ä¸€ç±»æ˜¯åŸºäºŽç”¨æˆ·ç›¸ä¼¼åº¦çš„推èï¼Œåˆ™æ˜¯å°†ä¸Žç›®æ ‡ç”¨æˆ·å…´è¶£ç›¸åŒçš„其他用户è´ä¹°çš„东西推èç»™ç›®æ ‡ç”¨æˆ·ï¼Œä¾‹å¦‚å°A历å²ä¸Šä¹°äº†ç‰©å“Bå’ŒC,ç»è¿‡ç®—法分æžï¼Œå‘现å¦ä¸€ä¸ªä¸Žå°A近似的用户å°Dè´ä¹°äº†ç‰©å“E,于是将物å“E推èç»™å°A。
两类推è都有å„自的优缺点,在一般的电商应用ä¸ï¼Œä¸€èˆ¬æ˜¯ä¸¤ç±»æ··åˆä½¿ç”¨ã€‚推è算法ä¸æœ€æœ‰å的算法就是ååŒè¿‡æ»¤ç®—法。
7ã€å…¶ä»–
除了以上算法之外,机器å¦ä¹ ç•Œè¿˜æœ‰å…¶ä»–çš„å¦‚é«˜æ–¯åˆ¤åˆ«ï¼Œæœ´ç´ è´å¶æ–¯ï¼Œå†³ç–æ ‘ç‰ç‰ç®—法。但是上é¢åˆ—çš„å…个算法是使用最多,影å“最广,ç§ç±»æœ€å…¨çš„典型。机器å¦ä¹ 界的一个特色就是算法众多,å‘展百花é½æ”¾ã€‚
下é¢åšä¸€ä¸ªæ€»ç»“,按照è®ç»ƒçš„æ•°æ®æœ‰æ— æ ‡ç¾ï¼Œå¯ä»¥å°†ä¸Šé¢ç®—法分为监ç£å¦ä¹ ç®—æ³•å’Œæ— ç›‘ç£å¦ä¹ 算法,但推è算法较为特殊,既ä¸å±žäºŽç›‘ç£å¦ä¹ ,也ä¸å±žäºŽéžç›‘ç£å¦ä¹ ,是å•ç‹¬çš„一类。
监ç£å¦ä¹ 算法:
线性回归,逻辑回归,神ç»ç½‘络,SVM
æ— ç›‘ç£å¦ä¹ 算法: èšç±»ç®—法,é™ç»´ç®—法
特殊算法: 推è算法
除了这些算法以外,有一些算法的åå—在机器å¦ä¹ 领域ä¸ä¹Ÿç»å¸¸å‡ºçŽ°ã€‚但他们本身并ä¸ç®—是一个机器å¦ä¹ 算法,而是为了解决æŸä¸ªåé—®é¢˜è€Œè¯žç”Ÿçš„ã€‚ä½ å¯ä»¥ç†è§£ä»–们为以上算法的å算法,用于大幅度æ高è®ç»ƒè¿‡ç¨‹ã€‚å…¶ä¸çš„代表有:梯度下é™æ³•ï¼Œä¸»è¦è¿ç”¨åœ¨çº¿åž‹å›žå½’,逻辑回归,神ç»ç½‘络,推è算法ä¸ï¼›ç‰›é¡¿æ³•ï¼Œä¸»è¦è¿ç”¨åœ¨çº¿åž‹å›žå½’ä¸ï¼›BP算法,主è¦è¿ç”¨åœ¨ç¥žç»ç½‘络ä¸ï¼›SMO算法,主è¦è¿ç”¨åœ¨SVMä¸ã€‚
5.机器å¦ä¹ 的应用–大数æ®
说完机器å¦ä¹ 的方法,下é¢è¦è°ˆä¸€è°ˆæœºå™¨å¦ä¹ çš„åº”ç”¨äº†ã€‚æ— ç–‘ï¼Œåœ¨2010年以å‰ï¼Œæœºå™¨å¦ä¹ 的应用在æŸäº›ç‰¹å®šé¢†åŸŸå‘挥了巨大的作用,如车牌识别,网络攻击防范,手写å—符识别ç‰ç‰ã€‚但是,从2010年以åŽï¼Œéšç€å¤§æ•°æ®æ¦‚念的兴起,机器å¦ä¹ 大é‡çš„应用都与大数æ®é«˜åº¦è€¦åˆï¼Œå‡ 乎å¯ä»¥è®¤ä¸ºå¤§æ•°æ®æ˜¯æœºå™¨å¦ä¹ 应用的最佳场景。
è¬å¦‚ï¼Œä½†å‡¡ä½ èƒ½æ‰¾åˆ°çš„ä»‹ç»å¤§æ•°æ®é”åŠ›çš„æ–‡ç« ï¼Œéƒ½ä¼šè¯´å¤§æ•°æ®å¦‚何准确准确预测到了æŸäº›äº‹ã€‚例如ç»å…¸çš„Google利用大数æ®é¢„测了H1N1在美国æŸå°é•‡çš„爆å‘。

图13 GoogleæˆåŠŸé¢„测H1N1
百度预测2014年世界æ¯ï¼Œä»Žæ·˜æ±°èµ›åˆ°å†³èµ›å…¨éƒ¨é¢„测æ£ç¡®ã€‚
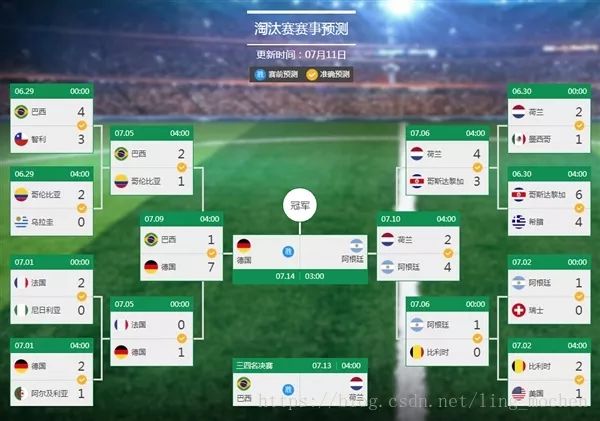
图14 百度世界æ¯æˆåŠŸé¢„测了所有比赛结果
è¿™äº›å®žåœ¨å¤ªç¥žå¥‡äº†ï¼Œé‚£ä¹ˆç©¶ç«Ÿæ˜¯ä»€ä¹ˆåŽŸå› å¯¼è‡´å¤§æ•°æ®å…·æœ‰è¿™äº›é”力的呢?简å•æ¥è¯´ï¼Œå°±æ˜¯æœºå™¨å¦ä¹ 技术。æ£æ˜¯åŸºäºŽæœºå™¨å¦ä¹ 技术的应用,数æ®æ‰èƒ½å‘挥其é”力。
大数æ®çš„æ ¸å¿ƒæ˜¯åˆ©ç”¨æ•°æ®çš„价值,机器å¦ä¹ 是利用数æ®ä»·å€¼çš„关键技术,对于大数æ®è€Œè¨€ï¼Œæœºå™¨å¦ä¹ 是ä¸å¯æˆ–缺的。相å,对于机器å¦ä¹ 而言,越多的数æ®ä¼šè¶Šå¯èƒ½æå‡æ¨¡åž‹çš„精确性,åŒæ—¶ï¼Œå¤æ‚的机器å¦ä¹ 算法的计算时间也迫切需è¦åˆ†å¸ƒå¼è®¡ç®—与内å˜è®¡ç®—è¿™æ ·çš„å…³é”®æŠ€æœ¯ã€‚å› æ¤ï¼Œæœºå™¨å¦ä¹ 的兴盛也离ä¸å¼€å¤§æ•°æ®çš„帮助。 大数æ®ä¸Žæœºå™¨å¦ä¹ 两者是互相促进,相ä¾ç›¸å˜çš„关系。
机器å¦ä¹ 与大数æ®ç´§å¯†è”系。但是,必须清醒的认识到,大数æ®å¹¶ä¸ç‰åŒäºŽæœºå™¨å¦ä¹ ,åŒç†ï¼Œæœºå™¨å¦ä¹ 也ä¸ç‰åŒäºŽå¤§æ•°æ®ã€‚大数æ®ä¸åŒ…å«æœ‰åˆ†å¸ƒå¼è®¡ç®—,内å˜æ•°æ®åº“,多维分æžç‰ç‰å¤šç§æŠ€æœ¯ã€‚å•ä»Žåˆ†æžæ–¹æ³•æ¥çœ‹ï¼Œå¤§æ•°æ®ä¹ŸåŒ…å«ä»¥ä¸‹å››ç§åˆ†æžæ–¹æ³•ï¼š
大数æ®ï¼Œå°åˆ†æžï¼šå³æ•°æ®ä»“库领域的OLAP分æžæ€è·¯ï¼Œä¹Ÿå°±æ˜¯å¤šç»´åˆ†æžæ€æƒ³ã€‚
大数æ®ï¼Œå¤§åˆ†æžï¼šè¿™ä¸ªä»£è¡¨çš„就是数æ®æŒ–掘与机器å¦ä¹ 分æžæ³•ã€‚
æµå¼åˆ†æžï¼šè¿™ä¸ªä¸»è¦æŒ‡çš„是事件驱动架构。
查询分æžï¼šç»å…¸ä»£è¡¨æ˜¯NoSQLæ•°æ®åº“。
也就是说,机器å¦ä¹ 仅仅是大数æ®åˆ†æžä¸çš„一ç§è€Œå·²ã€‚尽管机器å¦ä¹ 的一些结果具有很大的é”力,在æŸç§åœºåˆä¸‹æ˜¯å¤§æ•°æ®ä»·å€¼æœ€å¥½çš„说明。但这并ä¸ä»£è¡¨æœºå™¨å¦ä¹ 是大数æ®ä¸‹çš„唯一的分æžæ–¹æ³•ã€‚
机器å¦ä¹ 与大数æ®çš„结åˆäº§ç”Ÿäº†å·¨å¤§çš„价值。基于机器å¦ä¹ 技术的å‘展,数æ®èƒ½å¤Ÿâ€œé¢„测â€ã€‚对人类而言,积累的ç»éªŒè¶Šä¸°å¯Œï¼Œé˜…历也广泛,对未æ¥çš„判æ–越准确。例如常说的“ç»éªŒä¸°å¯Œâ€çš„人比“åˆå‡ºèŒ…åºâ€çš„å°ä¼™å更有工作上的优势,就在于ç»éªŒä¸°å¯Œçš„人获得的规律比他人更准确。而在机器å¦ä¹ é¢†åŸŸï¼Œæ ¹æ®è‘—å的一个实验,有效的è¯å®žäº†æœºå™¨å¦ä¹ 界一个ç†è®ºï¼šå³æœºå™¨å¦ä¹ 模型的数æ®è¶Šå¤šï¼Œæœºå™¨å¦ä¹ 的预测的效率就越好。 See below:
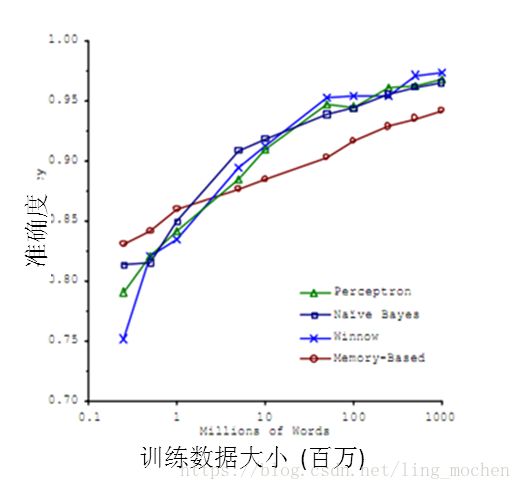

图15 机器å¦ä¹ 准确率与数æ®çš„关系
é€šè¿‡è¿™å¼ å›¾å¯ä»¥çœ‹å‡ºï¼Œå„ç§ä¸åŒç®—法在输入的数æ®é‡è¾¾åˆ°ä¸€å®šçº§æ•°åŽï¼Œéƒ½æœ‰ç›¸è¿‘的高准确度。于是诞生了机器å¦ä¹ 界的å言:æˆåŠŸçš„机器å¦ä¹ 应用ä¸æ˜¯æ‹¥æœ‰æœ€å¥½çš„算法,而是拥有最多的数æ®ï¼
在大数æ®çš„时代,有好多优势促使机器å¦ä¹ 能够应用更广泛。例如éšç€ç‰©è”网和移动设备的å‘展,我们拥有的数æ®è¶Šæ¥è¶Šå¤šï¼Œç§ç±»ä¹ŸåŒ…括图片ã€æ–‡æœ¬ã€è§†é¢‘ç‰éžç»“构化数æ®ï¼Œè¿™ä½¿å¾—机器å¦ä¹ 模型å¯ä»¥èŽ·å¾—越æ¥è¶Šå¤šçš„æ•°æ®ã€‚åŒæ—¶å¤§æ•°æ®æŠ€æœ¯ä¸çš„分布å¼è®¡ç®—Map-Reduce使得机器å¦ä¹ 的速度越æ¥è¶Šå¿«ï¼Œå¯ä»¥æ›´æ–¹ä¾¿çš„使用。ç§ç§ä¼˜åŠ¿ä½¿å¾—在大数æ®æ—¶ä»£ï¼Œæœºå™¨å¦ä¹ 的优势å¯ä»¥å¾—到最佳的å‘挥。
6.机器å¦ä¹ çš„å类–深度å¦ä¹
è¿‘æ¥ï¼Œæœºå™¨å¦ä¹ çš„å‘展产生了一个新的方å‘,å³â€œæ·±åº¦å¦ä¹ â€ã€‚
虽然深度å¦ä¹ 这四å—å¬èµ·æ¥é¢‡ä¸ºé«˜å¤§ä¸Šï¼Œä½†å…¶ç†å¿µå´éžå¸¸ç®€å•ï¼Œå°±æ˜¯ä¼ 统的神ç»ç½‘络å‘展到了多éšè—层的情况。
在上文介ç»è¿‡ï¼Œè‡ªä»Ž90年代以åŽï¼Œç¥žç»ç½‘络已ç»æ¶ˆå¯‚了一段时间。但是BP算法的å‘明人Geoffrey Hinton一直没有放弃对神ç»ç½‘ç»œçš„ç ”ç©¶ã€‚ç”±äºŽç¥žç»ç½‘络在éšè—层扩大到两个以上,其è®ç»ƒé€Ÿåº¦å°±ä¼šéžå¸¸æ…¢ï¼Œå› æ¤å®žç”¨æ€§ä¸€ç›´ä½ŽäºŽæ”¯æŒå‘é‡æœºã€‚2006年,Geoffrey Hinton在科å¦æ‚志《Science》上å‘è¡¨äº†ä¸€ç¯‡æ–‡ç« ï¼Œè®ºè¯äº†ä¸¤ä¸ªè§‚点:
多éšå±‚的神ç»ç½‘络具有优异的特å¾å¦ä¹ 能力,å¦ä¹ 得到的特å¾å¯¹æ•°æ®æœ‰æ›´æœ¬è´¨çš„刻画,从而有利于å¯è§†åŒ–或分类;
深度神ç»ç½‘络在è®ç»ƒä¸Šçš„难度,å¯ä»¥é€šè¿‡â€œé€å±‚åˆå§‹åŒ–†æ¥æœ‰æ•ˆå…‹æœã€‚

图16 Geoffrey Hinton与他的å¦ç”Ÿåœ¨Science上å‘表文ç«
é€šè¿‡è¿™æ ·çš„å‘现,ä¸ä»…解决了神ç»ç½‘络在计算上的难度,åŒæ—¶ä¹Ÿè¯´æ˜Žäº†æ·±å±‚神ç»ç½‘络在å¦ä¹ 上的优异性。从æ¤ï¼Œç¥žç»ç½‘络é‡æ–°æˆä¸ºäº†æœºå™¨å¦ä¹ ç•Œä¸çš„主æµå¼ºå¤§å¦ä¹ 技术。
åŒæ—¶ï¼Œå…·æœ‰å¤šä¸ªéšè—层的神ç»ç½‘络被称为深度神ç»ç½‘络,基于深度神ç»ç½‘络的å¦ä¹ ç ”ç©¶ç§°ä¹‹ä¸ºæ·±åº¦å¦ä¹ 。
由于深度å¦ä¹ çš„é‡è¦æ€§è´¨ï¼Œåœ¨å„æ–¹é¢éƒ½å–å¾—æžå¤§çš„关注,按照时间轴排åºï¼Œæœ‰ä»¥ä¸‹å››ä¸ªæ ‡å¿—性事件值得一说:
2012å¹´6月,《纽约时报》披露了Google Brain项目,这个项目是由Andrew Ngå’ŒMap-Reduceå‘明人Jeff Deanå…±åŒä¸»å¯¼ï¼Œç”¨16000个CPU Core的并行计算平å°è®ç»ƒä¸€ç§ç§°ä¸ºâ€œæ·±å±‚神ç»ç½‘络â€çš„机器å¦ä¹ 模型,在è¯éŸ³è¯†åˆ«å’Œå›¾åƒè¯†åˆ«ç‰é¢†åŸŸèŽ·å¾—了巨大的æˆåŠŸã€‚Andrew Ngå°±æ˜¯æ–‡ç« å¼€å§‹æ‰€ä»‹ç»çš„机器å¦ä¹ 的大牛(图1ä¸å·¦è€…)。
2012å¹´11月,微软在ä¸å›½å¤©æ´¥çš„一次活动上公开演示了一个全自动的åŒå£°ä¼ 译系统,讲演者用英文演讲,åŽå°çš„计算机一气呵æˆè‡ªåŠ¨å®Œæˆè¯éŸ³è¯†åˆ«ã€è‹±ä¸æœºå™¨ç¿»è¯‘,以åŠä¸æ–‡è¯éŸ³åˆæˆï¼Œæ•ˆæžœéžå¸¸æµç•…,其ä¸æ”¯æ’‘的关键技术是深度å¦ä¹ ï¼›
2013å¹´1月,在百度的年会上,创始人兼CEOæŽå½¦å®é«˜è°ƒå®£å¸ƒè¦æˆç«‹ç™¾åº¦ç ”究院,其ä¸ç¬¬ä¸€ä¸ªé‡ç‚¹æ–¹å‘就是深度å¦ä¹ ,并为æ¤è€Œæˆç«‹æ·±åº¦å¦ä¹ ç ”ç©¶é™¢(IDL)。
2013å¹´4月,《麻çœç†å·¥å¦é™¢æŠ€æœ¯è¯„论》æ‚志将深度å¦ä¹ 列为2013å¹´å大çªç ´æ€§æŠ€æœ¯(Breakthrough Technology)之首。

图17 深度å¦ä¹ çš„å‘展çƒæ½®
æ–‡ç« å¼€å¤´æ‰€åˆ—çš„ä¸‰ä½æœºå™¨å¦ä¹ 的大牛,ä¸ä»…都是机器å¦ä¹ 界的专家,更是深度å¦ä¹ ç ”ç©¶é¢†åŸŸçš„å…ˆé©±ã€‚å› æ¤ï¼Œä½¿ä»–们担任å„个大型互è”网公å¸æŠ€æœ¯æŽŒèˆµè€…çš„åŽŸå› ä¸ä»…åœ¨äºŽä»–ä»¬çš„æŠ€æœ¯å®žåŠ›ï¼Œæ›´åœ¨äºŽä»–ä»¬ç ”ç©¶çš„é¢†åŸŸæ˜¯å‰æ™¯æ— é™çš„深度å¦ä¹ 技术。
ç›®å‰ä¸šç•Œè®¸å¤šçš„图åƒè¯†åˆ«æŠ€æœ¯ä¸Žè¯éŸ³è¯†åˆ«æŠ€æœ¯çš„è¿›æ¥éƒ½æºäºŽæ·±åº¦å¦ä¹ çš„å‘展,除了本文开头所æçš„Cortanaç‰è¯éŸ³åŠ©æ‰‹ï¼Œè¿˜åŒ…括一些图åƒè¯†åˆ«åº”用,其ä¸å…¸åž‹çš„代表就是下图的百度识图功能。
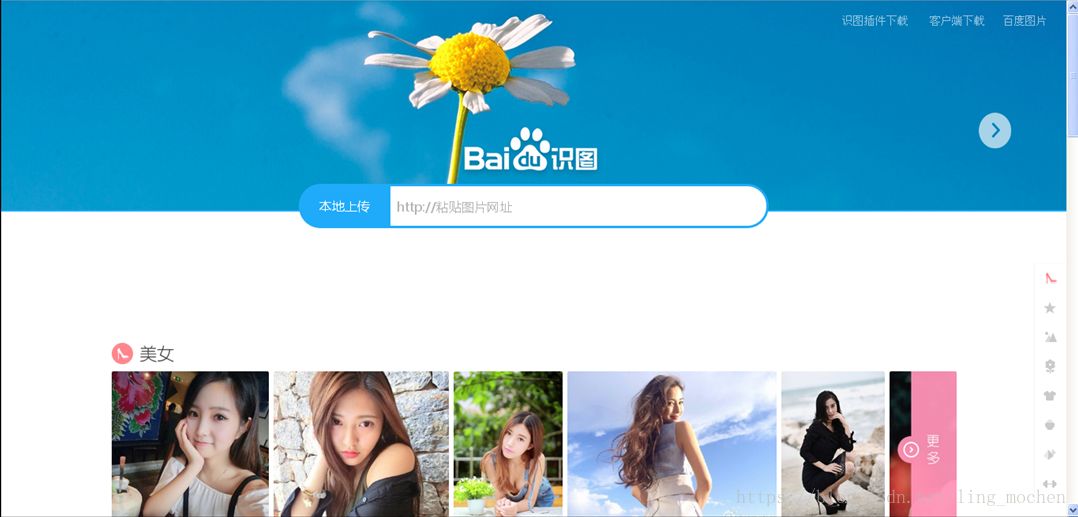
图18 百度识图
深度å¦ä¹ 属于机器å¦ä¹ çš„å类。基于深度å¦ä¹ çš„å‘展æžå¤§çš„促进了机器å¦ä¹ 的地ä½æ高,更进一æ¥åœ°ï¼ŒæŽ¨åŠ¨äº†ä¸šç•Œå¯¹æœºå™¨å¦ä¹ 父类人工智能梦想的å†æ¬¡é‡è§†ã€‚
7.机器å¦ä¹ 的父类–人工智能
人工智能是机器å¦ä¹ 的父类。深度å¦ä¹ 则是机器å¦ä¹ çš„å类。如果把三者的关系用图æ¥è¡¨æ˜Žçš„è¯ï¼Œåˆ™æ˜¯ä¸‹å›¾ï¼š
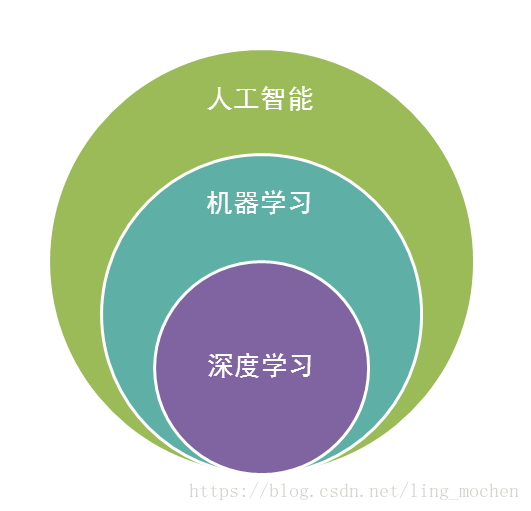
图19 深度å¦ä¹ ã€æœºå™¨å¦ä¹ ã€äººå·¥æ™ºèƒ½ä¸‰è€…关系
æ¯«æ— ç–‘é—®ï¼Œäººå·¥æ™ºèƒ½(AI)是人类所能想象的科技界最çªç ´æ€§çš„å‘明了,æŸç§æ„义上æ¥è¯´ï¼Œäººå·¥æ™ºèƒ½å°±åƒæ¸¸æˆæœ€ç»ˆå¹»æƒ³çš„åå—ä¸€æ ·ï¼Œæ˜¯äººç±»å¯¹äºŽç§‘æŠ€ç•Œçš„æœ€ç»ˆæ¢¦æƒ³ã€‚ä»Ž50年代æ出人工智能的ç†å¿µä»¥åŽï¼Œç§‘技界,产业界ä¸æ–åœ¨æŽ¢ç´¢ï¼Œç ”ç©¶ã€‚
这段时间å„ç§å°è¯´ã€ç”µå½±éƒ½åœ¨ä»¥å„ç§æ–¹å¼å±•çŽ°å¯¹äºŽäººå·¥æ™ºèƒ½çš„想象。人类å¯ä»¥å‘明类似于人类的机器,这是多么伟大的一ç§ç†å¿µï¼ä½†äº‹å®žä¸Šï¼Œè‡ªä»Ž50年代以åŽï¼Œäººå·¥æ™ºèƒ½çš„å‘展就磕磕碰碰,未有è§åˆ°è¶³å¤Ÿéœ‡æ’¼çš„科å¦æŠ€æœ¯çš„è¿›æ¥ã€‚
总结起æ¥ï¼Œäººå·¥æ™ºèƒ½çš„å‘展ç»åŽ†äº†å¦‚下若干阶段,从早期的逻辑推ç†ï¼Œåˆ°ä¸æœŸçš„ä¸“å®¶ç³»ç»Ÿï¼Œè¿™äº›ç§‘ç ”è¿›æ¥ç¡®å®žä½¿æˆ‘们离机器的智能有点接近了,但还有一大段è·ç¦»ã€‚直到机器å¦ä¹ 诞生以åŽï¼Œäººå·¥æ™ºèƒ½ç•Œæ„Ÿè§‰ç»ˆäºŽæ‰¾å¯¹äº†æ–¹å‘。基于机器å¦ä¹ 的图åƒè¯†åˆ«å’Œè¯éŸ³è¯†åˆ«åœ¨æŸäº›åž‚直领域达到了跟人相媲美的程度。机器å¦ä¹ 使人类第一次如æ¤æŽ¥è¿‘人工智能的梦想。
事实上,如果我们把人工智能相关的技术以åŠå…¶ä»–业界的技术åšä¸€ä¸ªç±»æ¯”,就å¯ä»¥å‘现机器å¦ä¹ 在人工智能ä¸çš„é‡è¦åœ°ä½ä¸æ˜¯æ²¡æœ‰ç†ç”±çš„。
人类区别于其他物体,æ¤ç‰©ï¼ŒåŠ¨ç‰©çš„最主è¦åŒºåˆ«ï¼Œä½œè€…认为是“智慧â€ã€‚而智慧的最佳体现是什么?
是计算能力么,应该ä¸æ˜¯ï¼Œå¿ƒç®—速度快的人我们一般称之为天æ‰ã€‚
是å应能力么,也ä¸æ˜¯ï¼Œå应快的人我们称之为çµæ•ã€‚
是记忆能力么,也ä¸æ˜¯ï¼Œè®°å¿†å¥½çš„人我们一般称之为过目ä¸å¿˜ã€‚
是推ç†èƒ½åŠ›ä¹ˆï¼Œè¿™æ ·çš„人我也许会称他智力很高,类似“ç¦å°”æ‘©æ–¯â€ï¼Œä½†ä¸ä¼šç§°ä»–拥有智慧。
æ˜¯çŸ¥è¯†èƒ½åŠ›ä¹ˆï¼Œè¿™æ ·çš„äººæˆ‘ä»¬ç§°ä¹‹ä¸ºåšé—»å¹¿ï¼Œä¹Ÿä¸ä¼šç§°ä»–拥有智慧。
想想看我们一般形容è°æœ‰å¤§æ™ºæ…§ï¼Ÿåœ£äººï¼Œè¯¸å¦‚庄å,è€åç‰ã€‚智慧是对生活的感悟,是对人生的积淀与æ€è€ƒï¼Œè¿™ä¸Žæˆ‘们机器å¦ä¹ çš„æ€æƒ³ä½•å…¶ç›¸ä¼¼ï¼Ÿé€šè¿‡ç»éªŒèŽ·å–规律,指导人生与未æ¥ã€‚没有ç»éªŒå°±æ²¡æœ‰æ™ºæ…§ã€‚

图20 机器å¦ä¹ 与智慧
那么,从计算机æ¥çœ‹ï¼Œä»¥ä¸Šçš„ç§ç§èƒ½åŠ›éƒ½æœ‰ç§ç§æŠ€æœ¯åŽ»åº”对。
例如计算能力我们有分布å¼è®¡ç®—,å应能力我们有事件驱动架构,检索能力我们有æœç´¢å¼•æ“Žï¼ŒçŸ¥è¯†å˜å‚¨èƒ½åŠ›æˆ‘们有数æ®ä»“库,逻辑推ç†èƒ½åŠ›æˆ‘们有专家系统,但是,唯有对应智慧ä¸æœ€æ˜¾è‘—特å¾çš„归纳与感悟能力,åªæœ‰æœºå™¨å¦ä¹ 与之对应。这也是机器å¦ä¹ 能力最能表å¾æ™ºæ…§çš„æ ¹æœ¬åŽŸå› ã€‚
让我们å†çœ‹ä¸€ä¸‹æœºå™¨äººçš„åˆ¶é€ ï¼Œåœ¨æˆ‘ä»¬å…·æœ‰äº†å¼ºå¤§çš„è®¡ç®—ï¼Œæµ·é‡çš„å˜å‚¨ï¼Œå¿«é€Ÿçš„检索,迅速的å应,优秀的逻辑推ç†åŽæˆ‘们如果å†é…åˆä¸Šä¸€ä¸ªå¼ºå¤§çš„智慧大脑,一个真æ£æ„义上的人工智能也许就会诞生,这也是为什么说在机器å¦ä¹ 快速å‘展的现在,人工智能å¯èƒ½ä¸å†æ˜¯æ¢¦æƒ³çš„åŽŸå› ã€‚
人工智能的å‘展å¯èƒ½ä¸ä»…å–决于机器å¦ä¹ ,更å–决于å‰é¢æ‰€ä»‹ç»çš„深度å¦ä¹ ,深度å¦ä¹ 技术由于深度模拟了人类大脑的构æˆï¼Œåœ¨è§†è§‰è¯†åˆ«ä¸Žè¯éŸ³è¯†åˆ«ä¸Šæ˜¾è‘—性的çªç ´äº†åŽŸæœ‰æœºå™¨å¦ä¹ 技术的界é™ï¼Œå› æ¤æžæœ‰å¯èƒ½æ˜¯çœŸæ£å®žçŽ°äººå·¥æ™ºèƒ½æ¢¦æƒ³çš„å…³é”®æŠ€æœ¯ã€‚æ— è®ºæ˜¯è°·æŒå¤§è„‘还是百度大脑,都是通过海é‡å±‚次的深度å¦ä¹ 网络所构æˆçš„。也许借助于深度å¦ä¹ 技术,在ä¸è¿œçš„å°†æ¥ï¼Œä¸€ä¸ªå…·æœ‰äººç±»æ™ºèƒ½çš„计算机真的有å¯èƒ½å®žçŽ°ã€‚
最åŽå†è¯´ä¸€ä¸‹é¢˜å¤–è¯ï¼Œç”±äºŽäººå·¥æ™ºèƒ½å€ŸåŠ©äºŽæ·±åº¦å¦ä¹ 技术的快速å‘展,已ç»åœ¨æŸäº›åœ°æ–¹å¼•èµ·äº†ä¼ 统技术界达人的担忧。真实世界的“钢é“ä¾ â€ï¼Œç‰¹æ–¯æ‹‰CEO马斯克就是其ä¸ä¹‹ä¸€ã€‚最近马斯克在å‚åŠ MITè®¨è®ºä¼šæ—¶ï¼Œå°±è¡¨è¾¾äº†å¯¹äºŽäººå·¥æ™ºèƒ½çš„æ‹…å¿§ã€‚â€œäººå·¥æ™ºèƒ½çš„ç ”ç©¶å°±ç±»ä¼¼äºŽå¬å”¤æ¶é”,我们必须在æŸäº›åœ°æ–¹åŠ 强注æ„。â€

图21 马斯克与人工智能
尽管马斯克的担心有些å±è¨€è€¸å¬ï¼Œä½†æ˜¯é©¬æ–¯å…‹çš„推ç†ä¸æ— é“ç†ã€‚“如果人工智能想è¦æ¶ˆé™¤åžƒåœ¾é‚®ä»¶çš„è¯ï¼Œå¯èƒ½å®ƒæœ€åŽçš„决定就是消ç人类。â€é©¬æ–¯å…‹è®¤ä¸ºé¢„防æ¤ç±»çŽ°è±¡çš„方法是引入政府的监管。
在这里作者的观点与马斯克类似,在人工智能诞生之åˆå°±ç»™å…¶åŠ 上若干规则é™åˆ¶å¯èƒ½æœ‰æ•ˆï¼Œä¹Ÿå°±æ˜¯ä¸åº”该使用å•çº¯çš„机器å¦ä¹ ,而应该是机器å¦ä¹ 与规则引擎ç‰ç³»ç»Ÿçš„综åˆèƒ½å¤Ÿè¾ƒå¥½çš„è§£å†³è¿™ç±»é—®é¢˜ã€‚å› ä¸ºå¦‚æžœå¦ä¹ 没有é™åˆ¶ï¼Œæžæœ‰å¯èƒ½è¿›å…¥æŸä¸ªè¯¯åŒºï¼Œå¿…é¡»è¦åŠ 上æŸäº›å¼•å¯¼ã€‚æ£å¦‚人类社会ä¸ï¼Œæ³•å¾‹å°±æ˜¯ä¸€ä¸ªæœ€å¥½çš„规则,æ€äººè€…æ»å°±æ˜¯å¯¹äºŽäººç±»åœ¨æŽ¢ç´¢æ高生产力时ä¸å¯é€¾è¶Šçš„ç•Œé™ã€‚
在这里,必须æ一下这里的规则与机器å¦ä¹ 引出的规律的ä¸åŒï¼Œè§„律ä¸æ˜¯ä¸€ä¸ªä¸¥æ ¼æ„义的准则,其代表的更多是概率上的指导,而规则则是神圣ä¸å¯ä¾µçŠ¯ï¼Œä¸å¯ä¿®æ”¹çš„。规律å¯ä»¥è°ƒæ•´ï¼Œä½†è§„则是ä¸èƒ½æ”¹å˜çš„。有效的结åˆè§„律与规则的特点,å¯ä»¥å¼•å¯¼å‡ºä¸€ä¸ªåˆç†çš„,å¯æŽ§çš„å¦ä¹ 型人工智能。
8.机器å¦ä¹ çš„æ€è€ƒâ€“计算机的潜æ„识
最åŽï¼Œä½œè€…想谈一谈关于机器å¦ä¹ 的一些æ€è€ƒã€‚主è¦æ˜¯ä½œè€…在日常生活总结出æ¥çš„一些感悟。
回想一下我在节1里所说的故事,我把å°Y过往跟我相约的ç»åŽ†åšäº†ä¸€ä¸ªç½—列。但是这ç§ç½—列以往所有ç»åŽ†çš„方法åªæœ‰å°‘数人会这么åšï¼Œå¤§éƒ¨åˆ†çš„人采用的是更直接的方法,å³åˆ©ç”¨ç›´è§‰ã€‚那么,直觉是什么?
å…¶å®žç›´è§‰ä¹Ÿæ˜¯ä½ åœ¨æ½œæ„识状æ€ä¸‹æ€è€ƒç»éªŒåŽå¾—出的规律。就åƒä½ 通过机器å¦ä¹ ç®—æ³•ï¼Œå¾—åˆ°äº†ä¸€ä¸ªæ¨¡åž‹ï¼Œé‚£ä¹ˆä½ ä¸‹æ¬¡åªè¦ç›´æŽ¥ä½¿
All In One Gaming PC is the best choice when you are looking higher level desktop type computer for heaver tasks, like engineering or architecture drawings, designing, 3D max, video or music editing, etc. What we do is Custom All In One Gaming PC, you can see Colorful All In One Gaming PC at this store, but the most welcome is white and black. Sometimes, clients may ask which is the Best All In One Gaming PC? 23.8 inch i7 or i5 11th generation All In One Gaming Desktop PC should beat it. Cause this configuration can finish more than 80% task for heavier jobs. Business All In One Computer and All In One Desktop Touch Screen is other two popular series. Multiple screens, cpu, storage optional. Except All In One PC, there are Education Laptop, Gaming Laptop, i7 16gb ram 4gb graphics laptop, Mini PC , all in one, etc.
Any other unique requirements, Just feel free contact us and share your idea, thus more details sended in 1-2working days. Will try our best to support you.
All In One Gaming PC,Best All In One Gaming Pc,Colorful All In One Gaming Pc,Custom All In One Gaming Pc,All In One Gaming Desktop Pc
Henan Shuyi Electronics Co., Ltd. , https://www.shuyicustomlaptop.com